
Makine öğrenmesi, verinin sınıflandırılması için oluşturulan bir matematiksel modele ait parametrelerin, veri üzerinden bulunması işlemidir. Önceki yazılaramızda değindiğimiz Lojistik Regresyon Analizi ve Karar Ağaçları gibi yöntemler birer makine öğrenmesi yöntemidir. Herhangi bir bilimsel yöntemde olduğu gibi makine öğrenmesinde de başarı kriterlerinin objektif olması gerekmektedir ve iki farklı makine öğrenmesi algoritmasının beklenen “başarısı” bu metrikler aracılığı ile ifade edilebilir olmalıdır. Bu nedenle literatürde makine öğrenmesinin başarısının raporlanması için farklı metrikler/ölçütler önerilmiştir. Bu yazımızda Doğruluk, Hatırlama, ROC, AUC, gibi makine öğrenmesi makalelerinde sıklıkla karşımıza çıkan terimlerin anlamlarını inceleyeceğiz.
Makine öğrenmesine yeni başlayan çoğu kişi için bir öğrenme algoritmasının başarısı verdiği doğru sonuçlar ile ilişkilendirilir. Ancak öğrenme algoritmasının kullanım alanına göre algoritmanın başarısı veremediği doğru yanıtlar veya verdiği yanlış yanıtlar ile de değerlendirilebilir.
Örneğin tıp alanında kanser riskini ölçmek için geliştirilen bir öğrenme algoritmasını ele alalım. Öğrenme algoritmasının test setinde yer alan hastalardan X1,X2,..,X7 de hastalık riski bulunmazken, X8,X9 ve X10 hastalık riski taşıyor olsun. Makine öğrenmesi uzmanı tarafından geliştirilen A ve B algoritmalarının hastaların risk olasılıklarını aşağıdaki tablodaki gibi hesapladıklarını ve olasılık $\tau=0.5$ eşik değerinden yüksek ise kişinin riskli grupta yer aldığını varsayalım.
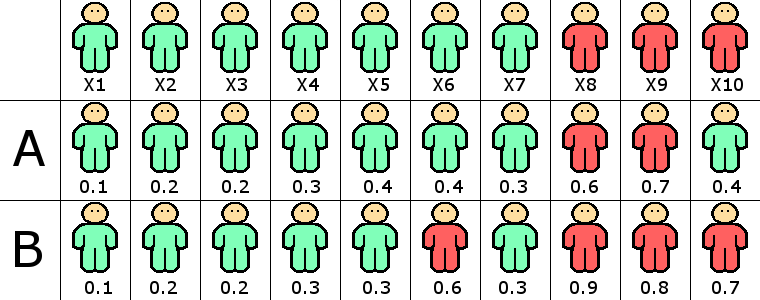
Bu durumda A algoritması X8 ve X9 kişilerinde kanser riski olduğunu, diğer hastların normal olduğu sonucunu üretirken, aynı uzman tarafından geliştirilen B algoritması ise X6,X8,X9 ve X10 kişilerinde risk olduğuna dair sonuçlar üretecektir.
Algoritma başarılarını algoritmanın doğru cevapları üzerinden hesaplarsak: A algoritmasının 9 doğru, 1 yanlış (X10); B algoritmasının da 9 doğru, 1 yanlış (X6) yaptığını buluruz. Bu metriğe göre iki algoritmanın da %90 başarılı olduğu raporlanacaktır. Ancak hepimizin bildiği gibi kanser gibi bir hastalıkta erken teşhis edilebilecek bir hastanın gözden kaçırılması ve “sağlıklı” raporu üretilmesi oldukça yıkıcı sonuçlara yol açabilmektedir. Bu nedenle B algoritmasının yaptığı hata daha kabul edilebilir bir hata iken, A algoritmasının hatası kabul edilemez bir hatadır. Peki iki algoritma arasındaki farkı nasıl ortaya çıkarabiliriz?
Karışıklık Matrisi (Confusion Matrix)
Karışıklık matrisi performans değerlendirmesinde önemli bir kavramdır. Yukarıdaki örnek problem için oluşturulacak karışıklık matrisinde hastalık riski taşıyan kişiler (X8,X9 ve X10) pozitif (Positive), taşımayan kişiler ise negatif (Negative) olarak isimlendirilir. Algoritma çıktılarına göre hastalık riski görülen kişiler “pozitif”, hastalık riski görülmeyen kişiler ise “negatif” olarak gruplanır. Bu gruplar 2x2 bir matris üzerinde aşağıdaki şekilde gösterilebilir:
| Tahmin A / Gerçek | Pozitif | Negatif | Toplam | Tahmin B / Gerçek | Pozitif | Negatif | Toplam | |
|---|---|---|---|---|---|---|---|---|
| Pozitif(P) | 2 | 0 | 2 | Pozitif(P) | 3 | 1 | 4 | |
| Negatif(N) | 1 | 7 | 8 | Negatif(N) | 0 | 6 | 6 | |
| Toplam | 3 | 7 | 10 | Toplam | 3 | 7 | 10 |
İlk tablodan A algoritmasının toplam iki “Pozitif”, sekiz “Negatif” sonucu ürettiği görülmektedir. Tablonun birinci satırı incelendiğinde, A algoritmasının pozitif örneklere “Pozitif” dediği (True Positive (TP)) örnek sayısı iki iken, negatif örneklere “Pozitif” dediği (False Positive (FP)) örnek sayısının sıfır olduğu görülür. Tablonun ikinci satırı incelendiğinde; A algoritmasının pozitif örneklere “Negatif” dediği (False Negative (FN)) bir örnek, negatif örneklere “Negatif” dediği (True Negative (TN)) yedi örnek bulunduğu görülür.
Benzer şekilde ikinci tablodan B algoritmasının toplam dört “Pozitif”, altı “Negatif” sonucu ürettiği görülmektedir. Tablonun birinci satırı incelendiğinde, B algoritmasının pozitif örneklere “Pozitif” dediği (True Positive (TP)) örnek sayısı üç iken, negatif örneklere “Pozitif” dediği (False Positive (FP)) örnek sayısının bir olduğu görülür. Tablonun ikinci satırı incelendiğinde; B algoritmasının pozitif örneklere “Negatif” dediği (False Negative (FN)) sıfır örnek, negatif örneklere “Negatif” dediği (True Negative (TN)) altı örnek bulunduğu görülür.
True Positive (TP) ve True Negative (TN) değerleri algoritmanın pozitif örneklere pozitif, negatif örneklere negatif deme sayılarını göstermektedir ve algoritmanın doğruluğunun (Accuracy) ölçülmesinde kullanılır. False Positive (FP) değeri algoritmanın negatif bir örneğe pozitif deme sayısını göstermektedir ve algoritmanın kesinliğinin (Precision) bir ölçüsü olarak kullanılır. False Negative (FN) değeri algoritmanın pozitif bir örneğe negatif deme sayısını göstermektedir ve algoritmanın hatırlama (Recall) gücünün bir ölçüsü olarak kullanılır.
Doğruluk (Accuracy)
Doğruluk değeri algoritmanın doğru sınıflandırdığı (TP+TN) örnek sayısının toplam örnek sayısına (TP+FP+FN+TN) oranıdır. Çoğu uygulamada algoritmanın başarısı olarak da verilmektedir. A ve B algoritmaları için doğruluk oranları aşağıdaki gibi hesaplanır:
\(ACC_A = \frac{TP+TN}{TP+FP+FN+TN} = \frac{2+7}{2+0+1+7}=0.9\) \(ACC_B = \frac{TP+TN}{TP+FP+FN+TN} = \frac{3+6}{3+1+0+6}=0.9\)
Hatırlama (Recall)
Hatırlama değeri algoritmanın pozitif örnekleri sınıflandırma başarısını ölçmektedir. Örnek problemimizde olduğu gibi hiç bir pozitif (riskli) örneğin sınıflandırma sonucunda unutulmaması (yanlışlıkla risksiz gruba sınıflandırılmaması) için hatırlama oranı yüksek bir sınıflandırıcı tercih edilmelidir. A ve B algoritmaları için hatırlama oranları aşağıdaki gibi hesaplanır:
\(R_A = \frac{TP}{TP+FN} = \frac{2}{2+1}=0.\overline{66}\) \(R_B = \frac{TP}{TP+FN} = \frac{3}{3+0}=1.0\)
Sonuçlardan da görüldüğü gibi test setimizde yer alan toplam üç riskli hastadan A algoritması iki tanesini hatırlayabilirken, B algoritması üçünü de riskli olarak hatırlayabilmiştir.
Kesinlik (Precision)
Kesinlik değeri algoritmanın pozitif dediği örneklerin (TP+FP) gerçekten pozitif olma olasılığını (TP) ölçmektedir. İncelediğimiz örnekte bir hastanın yanlışlıkla riskli görülmesi ve ilave tetkikler yapılması çok büyük bir sorun yaratmayacaktır. Ancak bu örneği riskli görülen hastalara kemoterapi uygulanacağı bilgisini eklersek, kesinlik değerinin de yüksek olması istenecektir ki hasta olmayan bir kişiye yanlışlıkla kemoterapi uygulanmasın. A ve B algoritmaları için kesinlik oranları aşağıdaki gibi hesaplanır:
\(P_A = \frac{TP}{TP+FP} = \frac{2}{2+0}=1.0\) \(P_B = \frac{TP}{TP+FP} = \frac{3}{3+1}=0.75\)
F-ölçüsü (F-measure)
Çoğu makine öğrenmesi algoritmasında hatırlama oranı artırılmak istendiğinde FP sayısı da arttığından kesinlik değeri düşmektedir. Yada kesinlik değeri artırılmak istendiğinde FN sayısı artacağından hatırlama oranı düşecektir. Hatırlama ve kesinlik oranlarının ikisinin de iyi olduğu bir algoritma aranması durumunda bu iki değerin harmonik ortalaması olan F-ölçüsü kullanılır. Biri küçük diğeri büyük iki sayının harmonik ortalaması alındığında sonuç küçük olana yakın çıkacağı için F-ölçüsünün yüksek çıkabilmesi için iki değerin (Kesinlik ve Hatırlama) de yüksek olması gereklidir. A ve B algoritmaları için F-ölçüleri aşağıdaki gibi hesaplanır:
\(F_A = \frac{2*R_A*P_A}{R_A+P_A} = \frac{2*0.\overline{66}*1.0}{0.\overline{66}+1.0}=0.8\) \(F_B = \frac{2*R_B*P_B}{R_B+P_B} = \frac{2* 1.0 * 0.75}{1.0+0.75}=0.\overline{857142}\)
A ve B algoritmalarını karşılaştırmaya başladığımızda “… ve olasılık $\tau=0.5$ eşik değerinden yüksek ise kişinin riskli grupta yer aldığını varsayalım” demiştik. Peki $\tau=0.5$ değerinin nereden bulmuştuk? $\tau=0.4$ eşik değerini seçsek algoritmanın başarısını ölçmek için hesapladığımız metrikler nasıl değişirdi? Bu gibi sorular bilimsel yayınlarda da sıklıkla karşımıza çıkan sorulardır. Genellikle üzerinde çalışılan problem için hangi metrik (doğruluk, hatırlama, kesinlik, F-ölçüsü) daha uygun görülüyor ise o metriği en yüksekleyen $\tau$ değeri seçilmektedir. Üzerinde çalışılan problem için tek bir metriğin uygun olmadığı durumlar içinse ROC (Receiver Operating Characteristic) adı verilen karakteristik eğriler/grafikler paylaşılmaktadır.
ROC Eğrileri (Receiver Operating Characteristic Curves)
Sabit bir $\tau$ değeri için oluşturulan karışıklık matrisinin hücreleri üzerinden TPR, TNR, FPR ve FNR (True Positive Rate, True Negative Rate, False Positive Rate and False Negative Rate) değerleri aşağıdaki şekilde hesaplanabilir.
-
TPR (sensitivity) değeri algoritmanın pozitif örnekleri sınıflandırma başarısını (hatırlama) ölçmektedir ve $TPR(\tau)=\frac{TP}{TP+FN}$ ifadesi ile hesaplanır.
-
TNR (specificity) değeri ise algoritmanın negatif örnekleri sınıflandırma başarısını ölçmektedir ve $TNR(\tau)=\frac{TN}{FP+TN}$ ifadesi ile hesaplanır.
-
FPR yanlış sınıflandırılan negatif örneklerin oranını göstermektedir ve $FPR(\tau) =\frac{FP}{TN+FP}$ hesaplanır.
-
FNR yanlış sınıflandırılan pozitif örneklerin oranını göstermektedir ve $FNR(\tau) =\frac{FN}{TP+FN}$ ifadesi ile hesaplanır.
Bu hesaplama $\tau \in [0,1]$ aralığında sonlu sayıda $\tau$ değeri için tekrarlandığında her $\tau$ değeri için TPR, FPR, TNR, FNR değerleri elde edilir. Aşağıda A ve B öğrenme algoritmalarına ilişkin TPR ve FPR değerlerini 10 farklı $\tau$ değeri için hesaplayan kod parçası verilmiştir.
float taus[10] = { 0.0f, 0.1f, 0.2f, 0.3f, 0.4f, 0.5f, 0.6f, 0.7f, 0.8f, 0.9f };
float resA[10] = { 0.1f, 0.2f, 0.2f, 0.3f, 0.4f, 0.4f, 0.3f, 0.6f, 0.7f, 0.4f };
float resB[10] = { 0.1f, 0.2f, 0.2f, 0.3f, 0.3f, 0.6f, 0.3f, 0.9f, 0.8f, 0.7f };
int class[10] = {0,0,0,0,0,0,0,1,1,1};
float tprA[10] = {0};
float fprA[10] = {0};
float tprB[10] = {0};
float fprB[10] = {0};
for(int t = 0; t < 10; t++)
{
int tpA = 0, tnA = 0, fpA = 0, fnA = 0;
int tpB = 0, tnB = 0, fpB = 0, fnB = 0;
for(int i = 0; i < 10; i++)
{
int classA = (resA[i] > taus[t]) ? 1 : 0;
int classB = (resB[i] > taus[t]) ? 1 : 0;
tpA += (class[i] == 1 && classA == 1) ? 1 : 0;
tnA += (class[i] == 0 && classA == 0) ? 1 : 0;
fpA += (class[i] == 0 && classA == 1) ? 1 : 0;
fnA += (class[i] == 1 && classA == 0) ? 1 : 0;
tpB += (class[i] == 1 && classB == 1) ? 1 : 0;
tnB += (class[i] == 0 && classB == 0) ? 1 : 0;
fpB += (class[i] == 0 && classB == 1) ? 1 : 0;
fnB += (class[i] == 1 && classB == 0) ? 1 : 0;
}
tprA[t] = (float)tpA / (float)(tpA + fnA);
fprA[t] = (float)fpA / (float)(fpA + tnA);
tprB[t] = (float)tpB / (float)(tpB + fnB);
fprB[t] = (float)fpB / (float)(fpB + tnB);
}
Yazılan kod parçasının çalıştırılması ile aşağıdaki tablo elde edilir. Veriler incelendiğinde $\tau$ değerinin küçük olduğu durumda algoritma her test örneğine”pozitif” sonucu ürettiğinden TPR ve FPR değerleri yüksek çıkarken, $\tau$ değerinin çok büyük seçilmesi durumunda ise algoritma her test örneğine “negatif” sonucu ürettiğinden TPR ve FPR değerleri düşük çıkmaktadır.
| $\tau$ | 0.0000 | 0.1000 | 0.2000 | 0.3000 | 0.4000 | 0.5000 | 0.6000 | 0.7000 | 0.8000 | 0.9000 |
|---|---|---|---|---|---|---|---|---|---|---|
| TPRA | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.6667 | 0.6667 | 0.3333 | 0.0000 | 0.0000 | 0.0000 |
| FPRA | 1.0000 | 0.8571 | 0.5714 | 0.2857 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| TPRB | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.6667 | 0.3333 | 0.0000 |
| FPRB | 1.0000 | 0.8571 | 0.5714 | 0.1429 | 0.1429 | 0.1429 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
Elde edilen bu değerlerin iki eksenli bir grafik üzerinde çizilmesi ile de ROC eğrileri elde edilir. Aşağıda FPR-TPR ikilisne ait ROC eğrisi (solda) çizilmiştir.
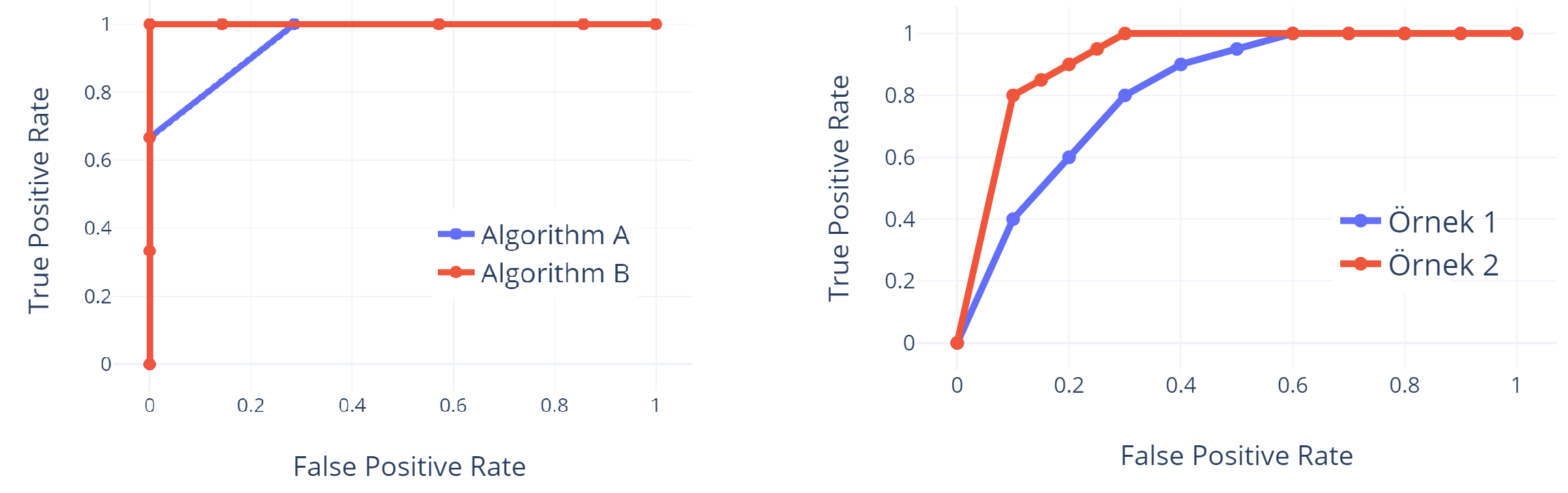
Not: Örnek için seçilen test seti sınırlı olduğundan elde edilen ROC eğrisi de tipik ROC eğrilerine benzememektedir. Bu nedenle sağ tarafta tipik bir ROC eğrisinin görüntüsü de paylaşılmıştır.
ROC eğrileri uygulama alanına göre kabul edilebilir bir FPR için, TPR değerinin ne seviyede olduğunu gösteren faydalı grafiklerdir. Örneğin sağ tarafta verilen örnek ROC eğrisi için yanlış pozitif oranının %20 olduğu durumda Örnek 2 algoritması %90 oranda pozitif örnekleri hatırlayabilirken, Örnek 1 algoritmasının %60 oranda pozitif örnekleri hatırlayabildiği görülmektedir.
AUC (Area Under the Curve)
AUC adından da anlaşıldığı üzere, ROC eğrisinin altında kalan alanı gösteren bir metriktir. Önceki metrikleri dikkatli incelendiğimizde ideal bir sınıflandırıcının FPR=0 iken TPR=1.0 dğerini üretmesi gerektiğini bekleyebiliriz. Bu durum ROC eğrisinin B algoritmasının ROC eğrisinde olduğu gibi basamak fonksiyonuna benzer bir yapıda olmasını gerektirir. Bu durmda da ROC eğrisinin altında kalan alan 1.0 olacaktır. Algoritma idealden uzaklaştıkça, Örnek 1’in ROC eğrisinde olduğu gibi eğri x eksenine yakın seyredeceğinden, eğrinin altında kalan alan da küçülecektir. A ve B sınıflandırıcaları için tablo kullanılarak $AUC_A \approx 1- \frac{(1-0.6667)*(0.2857)}{2}=0.952$ ve $AUC_B=1.0$ bulunur.
IoU (Intersection over Union)
IoU (kesişim/birleşim) daha önce bahsettiğimiz metriklerden farklı olarak, nesne tespitine yönelik geliştirilen makine öğrenme algoritmalarının başarısını ölçmek için kullanılan bir metriktir. Adından da anlaşılacağı üzere IoU; algoritma tarafından önerilen hedef bölgesinin (A), gerçek hedef bölgesi (B) ile kesişiminin, algoritma tarafından önerilen hedef bölgesinin gerçek hedef bölgesi ile birleşimine oranı ile hesaplanmaktadır. \(IoU = \frac{A \cap B}{A \cup B}\) Barkod Tanım ve Viola-Jones Yöntemi ile Nesne Tespiti gibi nesne konumunu tahmin eden algoritmalarda $IoU$ ilk hesaplanan başarı ölçütüdür. IoU değeri $[0,1]$ aralığında olduğundan, örneğimizde olduğu gibi olasılık değeri olarak da kullanılabilir. Bu durumda seçilen bir $\tau$ değeri için doğruluk, hatırlama, kesinlik gibi değerler hesaplanabileceği gibi, tespit algoritmasının başarısına ilişkin ROC eğrileri de paylaşılabilir.
Bu yazımızda makine öğrenmesi yayınlarında sıklıkla karşımıza çıkan terimlerin açıklamalırını yapmaya çalıştık. Yazımızın genelinden de anlaşılacağı üzere algoritma başarısını tek bir kritere/ölçüte göre sınıflandırmak mümkün değildir. Algoritma başarısı; algoritmanın kullanılacağı alana, algoritmanın tahammül edebileceği yanlış alarmlara (FP), algoritmanın göze alabileceği kaçırmalara (FN) göre değişmektedir. Bu noktada makine öğrenmesi uzamanına düşen görev seçeceği/eğiteceği algoritmada uygun metrikleri kullanarak algoritmaları kıyaslamak ve doğru algoritmayı bulmaktır.