
Karar Ağacları (Decision Trees) makine öğrenmesi ve veri analizinde kullanılan bir öğrenme/sınıflandırma yöntemidir. Günümüzde cep telefonu kameralarındaki yüz yakalama sisteminden, Kinect kameralarındaki hareket sınıflandırmasına kadar pek çok görüntü işleme uygulamasında ve moleküler biyoloji, finans ve tıp gibi diğer alanlarda sıklıkla kullanılmakta ve çok başarılı sonuçlar elde edilmektedir. Yöntemin bu kadar yaygın kullanılmasının en önemli nedeni çoğu makine öğrenmesi yöntemlerinin aksine beyaz-kutu (white box) bir öğrenme yöntemi olmasıdır. Yani eğitim tamamlandıktan sonra, yöntemin verdiği kararda verinin hangi bileşenin nasıl bir rol oynadığı gözlemlenebilir ve böylece veri daha kolay bir şekilde yorumlanabilir.
Yöntemin bir diğer avantajı ise eğitim sürecinin herhangi bir rastgelelik içermemesi ve ayarlanabilir parametrelerinin oldukça az olmasıdır. Bu nedenle aynı veri üzerinde bir kez çalıştırılarak elde edilen sonuçlar, yöntemin sonraki çalıştırılmalarında da aynı kalacaktır.
Karar ağaçları yöntemi hem anlama hem de gerçekleme yönünden makine öğrenmesi ve veri madenciliğinde kullanılan en anlaşılabilir yöntemlerden biridir. Yöntem her seferinde verinin bir özniteliğini (baz noktasını) kullanarak adi bir sınıflama yapar. Ardından bu adi sınıflandırma sonuçları üzerinde başka bir öznitelik kullanılarak tekrar adi bir sınıflama yapılır. Bu adi sınıflamaların art arda yapılması ile sonuçta oldukça kuvvetli bir sınıflayıcı elde edilir.
Kodlama kısmına geçmeden önce yöntemi basit bir örnekle anlamaya çalışalım. Aşağıda verilen tabloda 10 hastadan alınan yedi farklı test sonuçları (pozitif: “1”, negatif: “0”) paylaşılmıştır. Amacımız bu test sonuçlarını öznitelik/baz olarak kullanarak hastanın kalp krizi riski taşıyıp taşımadığına (riskli: “+1”, risksiz: “-1”) dair sonuca varabilecek bir makine öğretmesi yapmak.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B | Sonuç |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | -1 |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | -1 |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | -1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | -1 |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 | -1 |
| 1 | 0 | 1 | 1 | 0 | 1 | 1 | +1 |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | +1 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | +1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | +1 |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | +1 |
Yukarıda verilen tablo dikkatli incelenirse kalp krizi riski ile Yaş > 65 testinin yüksek derecede ilişkili olduğu görülür. Öyle ki yaşı 65 üstü olan altı hastadan dördünde risk bulunurken, 65 yaşından genç dört hastadan sadece bir tanesinde kalp krizi riski bulunmaktadır. Bu dört hastaya daha dikkatli bakmak için tabloyu sadece bu dört hasta (65 yaşından küçük kişiler) kalacak şekilde güncellersek aşağıdaki tablo elde edilir.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B | Sonuç |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | -1 |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | -1 |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 | -1 |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | +1 |
Bu tablodan da net bir şekilde görüldüğü üzere 65 yaşından küçük hastalarda kalp krizi riskini belirleyen en önemli öznitelik diyabet testidir. Benzer şekilde tabloyu sadece 65 yaş üstü hastalar kalacak şekilde düzenlersek aşağıdaki tablo elde edilir.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B | Sonuç |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | -1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | -1 |
| 1 | 0 | 1 | 1 | 0 | 1 | 1 | +1 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | +1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | +1 |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | +1 |
Bu tablodan da 65 yaş üstü hastalarda kalp krizi riskinin en çok sigara öz niteliği ile ilgili olduğu gözlemlenebilir. Analiz sayesinde şöyle bir sonuca varabiliriz: “Hasta 65 yaşından küçükse diyabet, büyükse sigara testi uygula. Eğer testlerin sonucu pozitif ise hastada kalp krizi riski bulunmakta, negatif ise hastada kalp krizi riski bulunmamaktadır.”
Yukarıda anlatımını yaptığımız bu işlemler ve vardığımız sonuç aşağıda verilen üç derinlikli bir ağaç yapısı ile gösterilebilir.
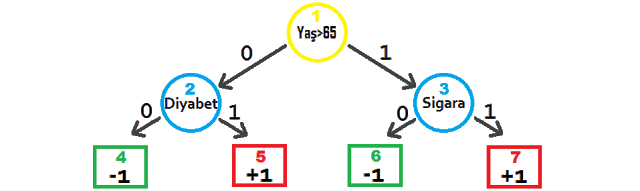
Karar ağacında her seferinde bir öznitelik seçilir ve bu özniteliğin pozitif (1) veya negatif (0) olmasına göre diğer öznitelikler seçilerek verinin gruplaması yapılır. Ağaç yapısında yuvarlaklar düğüm olarak adlandırılır ve her bir yuvarlakta bir öznitelik test edilir. Sarı yuvarlak kök düğümünü, mavi yuvarlaklar ise ara düğümleri göstermektedir. Dikdörtgenle çizilen kutular ise sonuç düğümlerini yani veriye atanan etiketleri göstermektedir.
Gelelim karar ağacını otomatik olarak oluşturma adımına. Yaptığımız işlemleri adım adım inceleyecek olursak en zor kısmın düğümleri seçmek olduğu görülecektir. Yukarıdaki örnekte Yaş > 65 özniteliğini neden seçtiğimizi hatırlayalım.
“Yukarıda verilen tablo dikkatli incelenirse kalp krizi riski ile Yaş > 65 testinin yüksek derecede ilişkili olduğu görülür.”
Burada “ilişki” ile kastedilen, Yaş > 65 özniteliğinin bilinmesi ile kalp krizi riski hakkında elde edilen bilgi miktarıdır. Bilgi kuramı ve makine öğrenmesinde bir özniteliğin taşıdığı bilgi $I(X)$ şu formül ile
ifade edilir: \(I(X) = H(Y)-H(Y|X)\)Burada $H(Y)$ fonksiyonu entropi fonksiyonu olarak bilinir ve içerisine aldığı özelliğin belirsizliğinin bir ölçüsüdür. Bu fonksiyonun değeri $p=Pr{Y=+1}$ olmak üzere; \(H(Y) = -p\log_2(p) - (1-p)\log_2(1-p)\)işlemi ile bulunur. Benzer şekilde koşullu entropi fonksiyonu $H(Y|X)$ ise $X$’ in bilinmesi durumunda $Y$’nin belirsizliğinin ölçüsüdür ve aşağıdaki formül ile bulunur. \(H(Y|X)=\sum_{x=0}^{1}\sum_{y=-1}^{+1}Pr\{X=x,Y=y\}\log_2(Pr\{Y=y|X=x\})\) $H(Y)$ entropi işlemini daha dikkatli inceleyecek olursak fonksiyonun en büyük değerini $p=0.5$ noktasında aldığını görürüz. Yani $Y$ özniteliğinde artı bir ve eksi birlerin sayısı bir birine ne kadar yakınsa $Y$’ nin değerinin o kadar belirsiz/tahmin edilemez olduğu söylenir. Benzer şekilde eğer $p=1$ ise $Y$ özniteliğinin tüm değerlerinin “+1” olduğu bilgisi kesindir ve dolayısıyla $Y$’ nin belirsizliği $H(Y)=0$’dır. Verilen formüller aşağıdaki fonksiyon şeklinde kodlanabilir.
float bilgi_miktari(double *data, int *label, int i, int *idx, int Nsample, int Nlength, float H[2][2])
{
float Py, Hy, Hyx;
for (int j=0; j < Nsample; j++)
{
H[ data[i+Nlength*idx[j]] > 0.5f ][ label[idx[j]] > 0.0 ] += 1.0f;
}
// Olasilik ve entropileri hesapla
Py = (H[0][0] + H[1][0])/ Nsample;
Hy = -Py*log2(Py)-(1-Py)*log2(1-Py);
if(H[0][0] == 0.0f || H[0][1] == 0.0f)
{
Hyx = 0.0f;
}
else
{
Hyx = H[0][0]*log2( H[0][0] / (H[0][0] + H[0][1])) + H[0][1]*log2( H[0][1] / (H[0][0] + H[0][1]));
}
if(H[1][0] == 0.0f || H[1][1] == 0.0f)
{
Hyx = Hyx;
}
else
{
Hyx += H[1][0]*log2( H[1][0] / (H[1][0] + H[1][1])) + H[1][1]*log2( H[1][1] / (H[1][0] + H[1][1]));
}
return Hy + Hyx/Nsample;
}
Kodda fonksiyona aktarılan i değişkeni seçilen özniteliği (yaş > 65, erkek, ..) göstermektedir. Yazılan bu koda yukarıda verilen tabloyu girdi olarak verirsek özniteliklerin içerdiği bilgi miktarları şu şekilde hesaplanır.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B |
|---|---|---|---|---|---|---|
| 0.12 | 0.03 | 0.12 | 0.03 | 0.03 | 0.03 | 0.12 |
Tabloya dikkat edilirse kök düğümü için en kuvvetli bileşenlerin yaş>65, sigara ve test b oldukları görülür. Yazılan kod bu bileşenler içerisinde ilk sıradakini seçtiğinden, kök düğümü yaş>65 şeklinde belirlenir. Bu işlemin ardından tablo iki parçaya ayrılarak, tüm bileşenler sınıflanana kadar her parça için bu işlemleri tekrarlamak gerekir. Yazımızda bu işlem ikiye_bol özyinelemeli fonksiyonu ile yapılmıştır.
void ikiye_bol(double *data, int *label, int *idx,int Nsample,int Nlength, int address, int max_depth, int *tree[2])
{
int i,j;
int oz = 0, om, Ixmax, K, L, N, P;
float Ig, Igmax = -1e10;
if (address > pow2(max_depth)-1 || Nsample==0) { return; }
for (j=0; j < Nsample; j++)
{
if(label[idx[0]] != label[idx[j]]) { oz = 1; break; }
}
if (oz != 1)
{
tree[0][address] = label[idx[0]]; // en olasi etiket
tree[1][address] = 0; // kimi bolecek
return;
}
for (i=0; i < Nlength; i++)
{
float H[2][2] = {0, 0, 0, 0};
Ig = bilgi_miktari(data, label, i, idx, Nsample, Nlength, H);
// En buyuk entropi ayrimini bul
if (Ig > Igmax)
{
Igmax = Ig;
Ixmax = i;
L = H[0][0] + H[0][1]; // ayrim sonrasi verideki #sifirlar
K = H[1][0] + H[1][1]; // ayrim sonrasi verideki #birler
N = H[0][0] + H[1][0]; // ayrim sonrasi etiketteki #negatifler
P = H[0][1] + H[1][1]; // ayrim sonrasi etiketteki #pozitifler
}
}
int *PosIx = (int*) malloc(K*sizeof(int));
int *NegIx = (int*) malloc(L*sizeof(int));
int posi = 0, negi = 0;
for(j=0; j < Nsample; j++)
{
if (data[Ixmax+Nlength*idx[j]] > 0.5) { PosIx[posi++] = idx[j]; }
else { NegIx[negi++] = idx[j]; }
}
// duruma gore en uygun etiketleri ata
tree[0][address] = P > N ? +1:-1;
tree[1][address] = Ixmax;
ikiye_bol(data, label, NegIx, L, Nlength, address*2+0, max_depth, tree);
ikiye_bol(data, label, PosIx, K, Nlength, address*2+1, max_depth, tree);
}
Kod içerisinde tüm öznitelikler test edilerek en uygun öznitelik seçilmekte ve bu özniteliğin değerine göre veri iki gruba ayrılmaktadır. Eğer örneğin seçilen özniteliği pozitif ise örneğin sırası PosIx vektörüne, negatif ise NegIx vektörüne atanır ve bu vektörler üzerinde tekrar ikiye_bol fonksiyonu çağrılır. Yukarıdaki tablo için PosIx=[1,3,5,7,8,9], NegIx=[0,2,4,6] dir. ikiye_bol fonksiyonu NegIx üzerinde çalıştırılırsa aşağıdaki tablo elde edilir.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B |
|---|---|---|---|---|---|---|
| 0.0 | 0.0 | 0.31 | 0.81 | 0.31 | 0.12 | 0.31 |
Tablo ikiye bölündüğünde yaş>65 ve erkek özniteliklerinin dört örneğinin de tamamı aynı değere sahip olduğundan bilgi miktarları sıfır olur. Diğer öznitelikler içerisinde de diyabet beklenildiği gibi en yüksek bilgi miktarına sahiptir. Aynı analiz PosIx vektörü üzerinde çalıştırılırsa da şu şekilde bir sonuç elde edilir.
| Yaş > 65 | Erkek | Sigara | Diyabet | Tansiyon | Test A | Test B |
|---|---|---|---|---|---|---|
| 0.0 | 0.11 | 0.92 | 0.04 | 0.0 | 0.04 | 0.04 |
Yine aynı nedenlerden dolayı yaş>65 özniteliğinin bilgi miktarı sıfırdır ve beklendiği üzere sigara özniteliğinin içerdiği bilgi miktarı en büyük olmuştur. Bu ölçümler sonucu diyabet ve sigara özniteliği seçilerek ikiye_bol fonksiyonu çağrıldığında tüm örnekler doğru sınıflandırıldığından işlem sona erecektir.
Yukarıda verilen fonksiyonları herhangi bir veri üzerinde çağırmak içinse aşağıda verilen fonksiyon kullanılmalıdır.
void karar_agaci(double *data, int *label, int *tree[2], int Nsample, int Nlength, int max_depth)
{
memset(tree[0], 0, pow2(max_depth)*sizeof(int));
memset(tree[1], 0, pow2(max_depth)*sizeof(int));
int *idx = (int*) malloc(Nsample*sizeof(int));
for(int i = 0; i < Nsample; i++) { idx[i] = i; }
ikiye_bol(data, label, idx, Nsample, Nlength, 1, max_depth, tree);
temizle(tree, max_depth);
}
Bu kod parçası ikiye_bol fonksiyonunu ilk çağrım için uygun parametrelerle çağırmak için yazılmıştır. İlk çağrımda veri herhangi bir gruba ayrılmadığından verinin tüm elemanları idx vektörü içerisinde fonksiyona gönderilmiştir. Ayrıca karar ağacının çok fazla büyümemesi için de bir derinlik sınırı koyulmuştur.
Kod içerisinde karar ağacı tree adlı $2\times P$ matriste saklanmıştır. Burada $P$ ağaçtaki düğüm sayısını göstermekte ve $P=2^\text{max_depth}$ işlemi ile hesaplanmaktadır. Matrisin ilk satırında o düğüme ulaşan bir veriye atanacak etiket bilgisi, ikinci satırında ise o düğümü en iyi ayıran özniteliğin sıra numarası tutulmaktadır. Örnek tablomuz için oluşan ağaç yapısının içeriği şu şekildedir.
TREE\[1\]: Oz Nitelik: 0, Etiket: -1
TREE\[2\]: Oz Nitelik: 3, Etiket: -1
TREE\[3\]: Oz Nitelik: 2, Etiket: +1
TREE\[4\]: Oz Nitelik: 0, Etiket: -1
TREE\[5\]: Oz Nitelik: 0, Etiket: +1
TREE\[6\]: Oz Nitelik: 0, Etiket: -1
TREE\[7\]: Oz Nitelik: 0, Etiket: +1
Bu tabloya göre karar aşamasında ilkin sıfır numaralı özniteliğe (yaş>65) bakıyoruz. Eğer bu özniteliğin değeri sıfır ise iki numaralı düğüme (TREE[2]) geçerek üç numaralı özniteliğe (diyabet), bakıyoruz. Bu özniteliğin değeri negatif ise dört numaralı düğüme (TREE[4]) geçiyor ve sonucu -1 olarak, pozitif ise beş numaralı düğüme geçerek sonucu +1 olarak döndürüyoruz. Yaş>65 özniteliğinin değeri bir ise de üç numaralı düğüme (TREE[3]) geçiyoruz. Bu düğümde sigara özniteliğini kontrol ediyor ve öznitelik sıfır ise altı numaralı düğüme geçerek sonucu -1, öznitelik bir ise de yedi numaralı düğüme geçerek sonucu +1 olarak belirliyoruz.
Sınıflama için yaptığımız bu işlemleri kodlamak oldukça kolaydır ve hız sadece ağacın derinliğine bağlıdır. Sınıflama için yazılan kod şu şekildedir.
void predict(double *data, int *tree[2], int *label, int Ntest, int Nlength, int max_depth)
{
int i,j,idx = 1;
for(j = 0; j < Ntest; j++) {
idx = 1;
int kts = Nlength*j;
for(i = 0; i < max_depth-1; i++) { idx = 2*idx + data[tree[1][idx] + kts]; }
label[j] = tree[0][idx];
}
}
Yazılan kodda idx değişkeni kök düğümü gösterecek şekilde (idx=1) ayarlanır. Ardından ilk adımda test sonucu “1” ise idx = 3, “0” ise idx = 2 olacak şekilde $idx = 2\times idx + test$ işlemine tabi tutulur. Ağaç yapısı dikkatli incelenirse bu döngü sonucunda ulaşacağımız son düğüm vermemiz gereken kararı söyleyen düğüm olacaktır.
Lojistik regresyon yazımızda da yaptığımız üzere bu yazımızda da örnek ve testler kısmını sonraki paylaşımlara bırakalım. Bu yazımızda kullandığımız ağaç yapısı (ikili karar ağaçları) ve algoritması (ID3) hakkında farklı kaynaklar okumak, kullanım alanlarına göz atmak isterseniz yazının referanslar kısmını inceleyebilirsiniz.
Referanslar
- Markuš, Nenad, et al. “A Method for Object Detection Based on Pixel Intensity Comparisons Organized in Decision Trees.” arXiv preprint arXiv:1305.4537 (2013).
- Quinlan, J. Ross. “Induction of decision trees.” Machine learning 1.1 (1986): 81-106.
- CIS 520 Machine Learning Lecture: Decision Trees