
Temel Bileşen Analizi (Principal Component Analysis), bir veri setinin en küçük karesel ortalama hata ile bir alt uzaya (genelde daha küçük boyutlu) izdüşümünü sağlayan dönüşüm matrisini bulmamıza yarayan bir analiz yöntemidir. Temel Bileşen Analizi (TBA) yüksek boyutlu verilerin daha düşük boyutlara indirilerek görselleştirilmesinde, veri setinin gürültüden arındırılmasında, izdüşüm sonrası elde edilen değerlerin bir araya getirilerek kullanılması durumunda ise yüz tanıma, karakter tanıma gibi uygulamalarda öznitelik olarak kullanılabilmektedir. Bu yazımızda TBA’ nin matematiksel olarak nasıl hesaplanacağı ispatlandıktan sonra, eğitimcisiz boyut indirgeme yöntemi olarak nasıl çalıştığı incelenecektir.
Özdeğer ve Özvektörler yazımızda büyük bir veri setinin kovaryans matrisinin özdeğer ve özvektör analizi yapıldığında, özvektörlerin verinin en yüksek değişintiyi gösterdiği düzlemi/ekseni, özdeğerlerin ise bu düzlemdeki değişinti miktarını gösterdiğini söylemiştik. Şimdi bu söylemimizi TBA’ nin yazımızda verilen tanımını, “bir veri setinin en küçük karesel ortalama hata ile daha küçük boyutlu bir alt uzaya izdüşümünü sağlayan dönüşüm matrisini bulmamıza yarayan bir analiz yöntemidir”, kullanarak ispatlayalım.
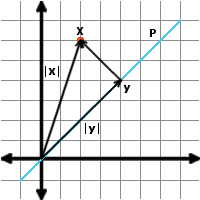
Yukarıda verilen şekilde verilen $\mathbf{x} \in \mathbb{R}^D$, $D$ boyutlu uzayda tanımlı bir nokta olsun. Bu noktanın $P$ doğrusu üzerindeki izdüşüm vektörü, $P$ doğrultusundaki birim vektör $\mathbf{p}$ kullanılarak $\mathbf{y}=\mathbf{p}\mathbf{x}^\intercal \mathbf{p}$ işlemi ile bulunur.
Bu durumda Pisagor teoremi yardımı ile izdüşüm hatasının karesi aşağıdaki formül ile hesaplanabilir.
\[\left\lVert\mathbf{y}-\mathbf{x}\right\lVert ^2 =\left\lVert\mathbf{x}\right\lVert ^2-\left\lVert\mathbf{y}\right\lVert ^2 = \mathbf{x}^\intercal\mathbf{x}-\mathbf{p}^\intercal \mathbf{x}\mathbf{x}^\intercal\mathbf{p} \tag{1}\]Elimizde $\mathbf{x}$ noktalarından $N$ tane olması durumunda Denklem $\eqref{1}$ kullanılarak ortalama karesel hata $\mathcal{L}\left (\mathbf{p} \right )$ aşağıdaki şekilde yazılabilir:
\[\mathcal{L}\left (\mathbf{p} \right )=\frac{1}{N}\sum_{n=1}^{N}\left\lVert\mathbf{y_n}-\mathbf{x_n}\right\lVert ^2 = \underbrace{\frac{1}{N}\sum_{n=1}^{N}{\mathbf{x_n}^\intercal\mathbf{x_n}}}_{2a} - \underbrace{\frac{1}{N}\sum_{n=1}^{N}{\mathbf{p}^\intercal \mathbf{x_n}\mathbf{x_n}^\intercal\mathbf{p}}}_{\text{2b}} \tag{2}\]Amacımız hatanın en küçük olduğu $P$ doğrusunu bulmak olduğundan, $\mathcal{L}\left (\mathbf{p} \right )$ maliyet fonksiyonu $\mathbf{p}$ değişkeni üzerinden optimize edilmelidir. Denklem $\eqref{2}$ de yer alan $\text{2a}$ ifadesi $\mathbf{p}$ ye bağlı olmadığından optimizasyona bir katkısı yoktur. Bu terim çıkarıldığında ve $\mathbf{C} = \frac{1}{N}\sum_{n=1}^{N}{\mathbf{x_n}\mathbf{x_n}^\intercal}$ tanımlandığında, $\mathcal{L}\left (\mathbf{p} \right )$ maliyet fonksiyonunun en küçüklenmesi problemi aşağıdaki optimizasyon problemine dönüşür:
\[\underset{\mathbb{p}}{\text{maximize}} \quad \mathbf{p}^\intercal \mathbf{C} \mathbf{p} \quad s.t \quad \left \lVert \mathbf{p} \right \lVert ^2=1\tag{3}\]Denklem $\eqref{3}$ ile verilen optimizasyon problemi Lagrange Çarpanları yardımı ile çözülebilir. $\lambda$ Lagrange çarpanı kullanılarak $\eqref{3}$ ile verilen maliyet fonksiyonu aşağıdaki şekilde ifade edilir:
\[\mathcal{L}\left (\mathbf{p},\lambda \right ) = \mathbf{p}^\intercal \mathbf{C} \mathbf{p} - \lambda \left ( \mathbf{p}^\intercal \mathbf{p} - 1 \right ) \tag{4}\]Denklem $\eqref{4}$ ile verilen maliyet fonksiyonun $\lambda$ değişkenine göre türevi alınıp sıfıra eşitlenirse $\mathbf{p}^\intercal \mathbf{p}=1$ bulunur.
Denklem $\eqref{4}$ in $\mathbf{p}$ ye göre türevi alınıp sıfıra eşitlenirse de
\[\frac{\partial{\mathcal{L}\left (\mathbf{p},\lambda \right ) }}{\partial{\mathbf{p}}}=2\mathbf{C}\mathbf{p}-2\lambda \mathbf{p} = 0 \implies \mathbf{C}\mathbf{p} = \lambda \mathbf{p} \tag{5}\]bulunur. Denklem $\eqref{5}$ ifadesi Özdeğer ve Özvektörler yazımızı hatırlayanlar için tanıdık bir ifadedir. Denklem $\eqref{5}$ şeklinde verilen bir problemin çözümünü sağlayan $\mathbf{p}$ vektörleri $\mathbf{C}$ matrisinin özvektörleri, $\lambda$ değerleri ise $\mathbf{C}$ matrisinin özdeğerleri olarak bilinir. Hesaplanabilecek tüm özvektör ve özdeğerler $\mathbf{P}=\left [ \mathbf{p_1},\mathbf{p_2},\dots,\mathbf{p_D} \right ]$ ve $\mathbf{\lambda} = \left [ \lambda_1, \lambda_2, \dots, \lambda_D\right ]$, $\mathbf{X}\in \mathcal{R}^{D\times N}$ matrisinin temel bileşenlerini oluşturmaktadır.
İfadede yer alan $\mathbf{C}=\frac{1}{N}\sum_{n=1}^{N}{\mathbf{x_n}\mathbf{x_n}^\intercal}$ matrisinin de sıfır ortalamalı bir $\mathbf{x_n}$ veri seti için kovaryans (özdeğişinti) matrisi olduğu dikkate alınırsa; bir veri setinin en küçük karesel ortalama hata ile daha küçük boyutlu bir alt uzaya izdüşümünü sağlayan dönüşüm matrisininin; verinin kovaryans matrisinin özvektörleri olduğu sonucuna ulaşılır.
Temel Bileşen Analizi C Kodu
Özdeğer ve Özvektörler yazımızda özdeğer ve özvektörlerin IMLAB içerisinde yer alan eig fonksiyonu yardımıyla hesaplanabileceğini görmüştük. Kovaryans hesaplamak için de kütüphanede yer alan covariance fonksiyonu kullanılarak Temel Bileşen Analizi aşağıdaki verilen kod parçassı ile hesaplanabilmektedir.
// compute the PCA of the input
void pca(matrix_t *input, matrix_t *eigValues, matrix_t *eigVectors)
{
// input: DxN features where N is the number of sample and D is the dimension of the data
int i, j;
// allocate covariance matrix
matrix_t *cov = matrix_create(float, rows(input), rows(input), 1);
// find covariance matrix of the input matrix
for (i = 0; i < rows(input); i++)
{
for(j = 0; j < rows(input); j++)
{
atf(cov, i, j) = covariance(data(float, input, i, 0, 0), data(float, input, j, 0, 0), cols(input));
}
}
// compute the principal components of the input
eig(cov, eigValues, eigVectors);
// remove unused covariance matrix
matrix_free(&cov);
}
Kod parçası girdi olarak verilen sıfır ortalamalı (ortalaması çıkartılmış) $X\in \mathbb{R}^{D \times N}$ matrisini kullanarak ilk olarak $D \times D$ boyutlu kovaryans matrisini ($C$) hesaplamaktadır. Ardından $C$ matrisi üzerinde Jacobi iterasyonu kullanılarak özdeğer ve özvektörler bulunmaktadır. Bulunan özdeğer ve özvektörler girdi matrisi $X$ in temel bileşenlerini oluşturmaktadır.
Temel Bileşen Analizi ile Boyut İndirgeme
Büyük veri işlemede ve veri madenciliğinde verinin görselleştirilebilmesi ve veri hakkında çıkarımların yapılabilmesi için $D$ boyutlu uzayda yer alan bir verinin çeşitliliği korunarak yani en az kayıp ile daha küçük boyutlu $K={2,3,4}$ bir uzaya taşınması gerekir. Yazımızın konusu olan Temel Bileşen Analizi günümüzde eğitimcisiz boyut indirgeme (unsupervised dimensionality reduction) yöntemleri arasında akla gelen ilk yöntemdir.
TBA sonucu bulunan özvektörlere karşı gelen özdeğerler, verinin o özvektör eksenindeki değişinti miktarını göstermektedir. $D$ boyutlu öznitelik uzayında, tüm öznitelikler birbirine dik değilse (çoğu zaman öznitelikler birbiri ile ilintilidir), yapılan TBA sonrasında değişinti miktarları analiz edildiğinde bir grup özvektör ile yapılan izdüşümün değişintinin çok az olduğu görülür. Veri setindeki toplam değişintinin $\tau=0.9$ oranında ($\%90$) korunarak boyut indirgeme yapılmak istendiğinde şu adımlar izlenmelidir:
- özdeğer ve karşı gelen özvektörleri ($\lambda_i$) büyükten küçüğe sıralanır
- $\mathcal{t}= \tau\sum_i{\lambda_i}$ ihtiyaç duyulan toplam değişinti hesaplanır
- $\min_{K} \sum_{i=1}^{K}{\lambda_i} > \mathcal{t}$ şartını sağlayan $K$ değeri bulunur
Bu işlem sonrasında bulunan $K$ değeri, $x\in \mathbb{R}^D$ uzayından verinin toplam değişintisinin $\tau$ oranında korunarak $y\in \mathbb{R}^K$ uzayına izdüşüm yapılabileceğini gösterir. Tüm veri seti için boyut indirgeme şu şekilde yapılır: \(\mathbf{Y}_{K\times N} = \left [ \mathbf{p_1},\mathbf{p_2},\dots,\mathbf{p_K} \right ]^{\intercal}\mathbf{X}_{D \times N}\)Temel Bileşen Analizi ile boyut indirgeme örneği için Mor İris Çiçeği (Iris Database) kullanılmıştır. Bu veri seti Ronald Fisher’ in iris çiçeğinin üç türünü ayırt etmek için yaptığı $N=150$ uzunluk ölçümünü içermektedir. Ölçümler çiçeğin taç yaprağının (petal) ve çanak yaprağının (sepal) uzunluk ve genişlikleri olmak üzere $D=4$ boyutlu bir uzaydadır.
Mor İris Çiçeği veri seti üzerinde TBA yapıldığında özdeğer vektörü $\mathbf{\lambda} = \left [0.02, 0.08, 0.24, 4.20\right ]$ şeklinde bulunur. Vektör incelendiğinde en yüksek iki özdeğer ($\lambda_4, \lambda_3$) ve özvektör ($\mathbf{p_4},\mathbf{p_3}$) seçildiğinde veri setindeki çeşitliliğin $\frac{4.20 + 0.24}{0.02+0.08+0.24+4.20}=\%92.5$ inin korunduğu görülür. $\mathbf{p_4}$ ve $\mathbf{p_3}$ özvektörleri ile yapılan izdüşüm sonrasında oluşan iki boyutlu veri aşağıdaki grafikte gösterilmiştir.
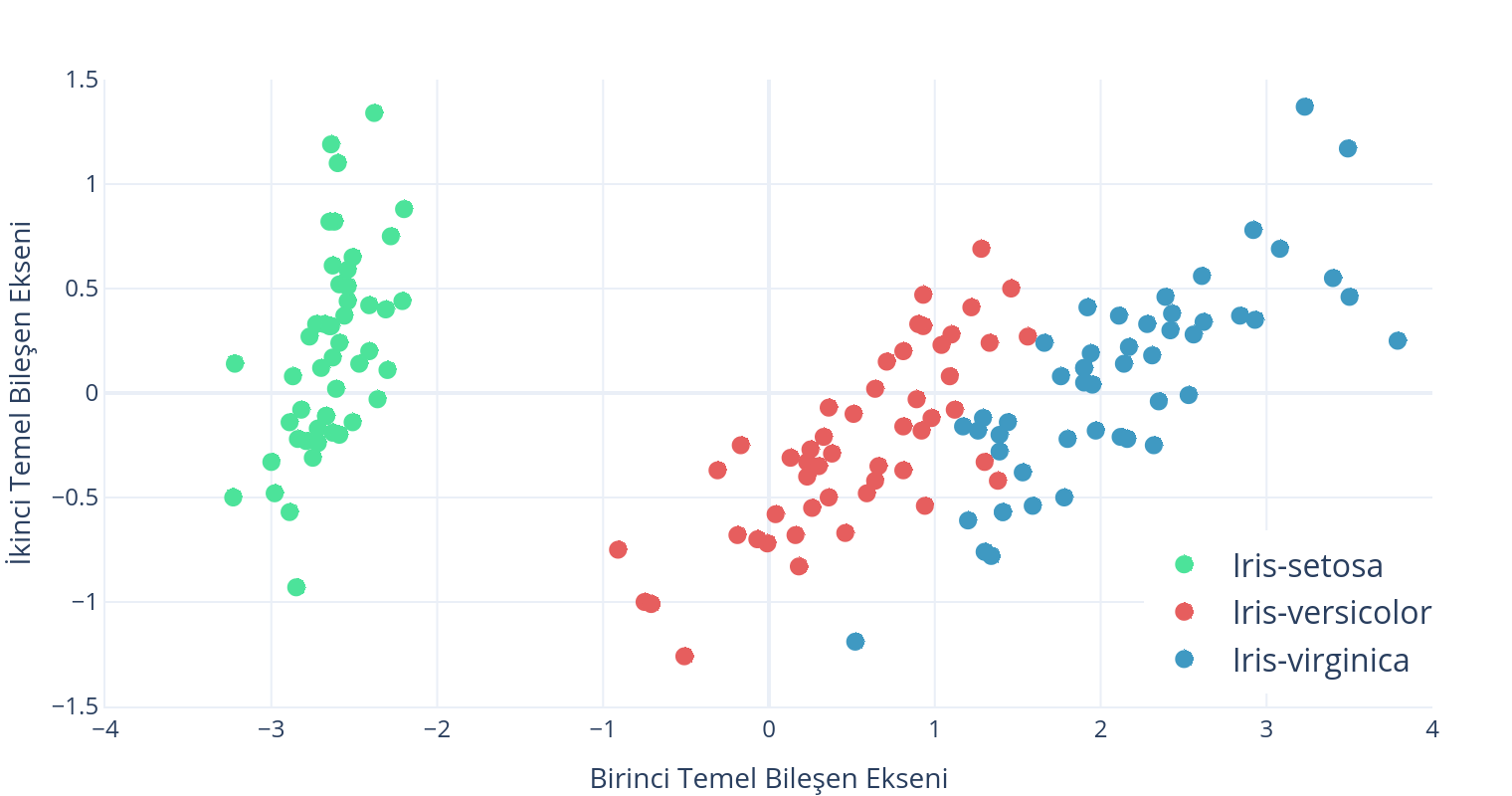
Grafikten de görüldüğü gibi veri setinin değişintisinin çok büyük bir kısmı birinci temel bileşen doğrultusunda gerçekleşmektedir. Böyle bir veri seti için sadece birinci temel bileşen doğrultusundaki izdüşümler ($y$ ekseni tüm veriler için sıfır olsa dahi) kullanılsa dahi veri setinin neredeyse tamamı doğru sınıflandırılabilmektedir.
Temel Bileşen Analizi Yönteminin Çalışmadığı Durumlar
Temel Bileşen Analizi her ne kadar eğitimcisiz boyut indirgeme yöntemleri arasında akla gelen ilk yöntem olsa da sınıfların en büyük değişintinin bulunduğu eksen yönünde dağılmadığı durumlarda (çok nadir) boyut indirgeme amacı ile kullanılamamaktadır. Aşağıda oluşturulan kasıtlı örnekte bu durum görselleştirilmiştir. A ve B sınıflarını ayırmak için yapılan iki öznitelikli ölçümler soldaki grafikte verilmiştir.
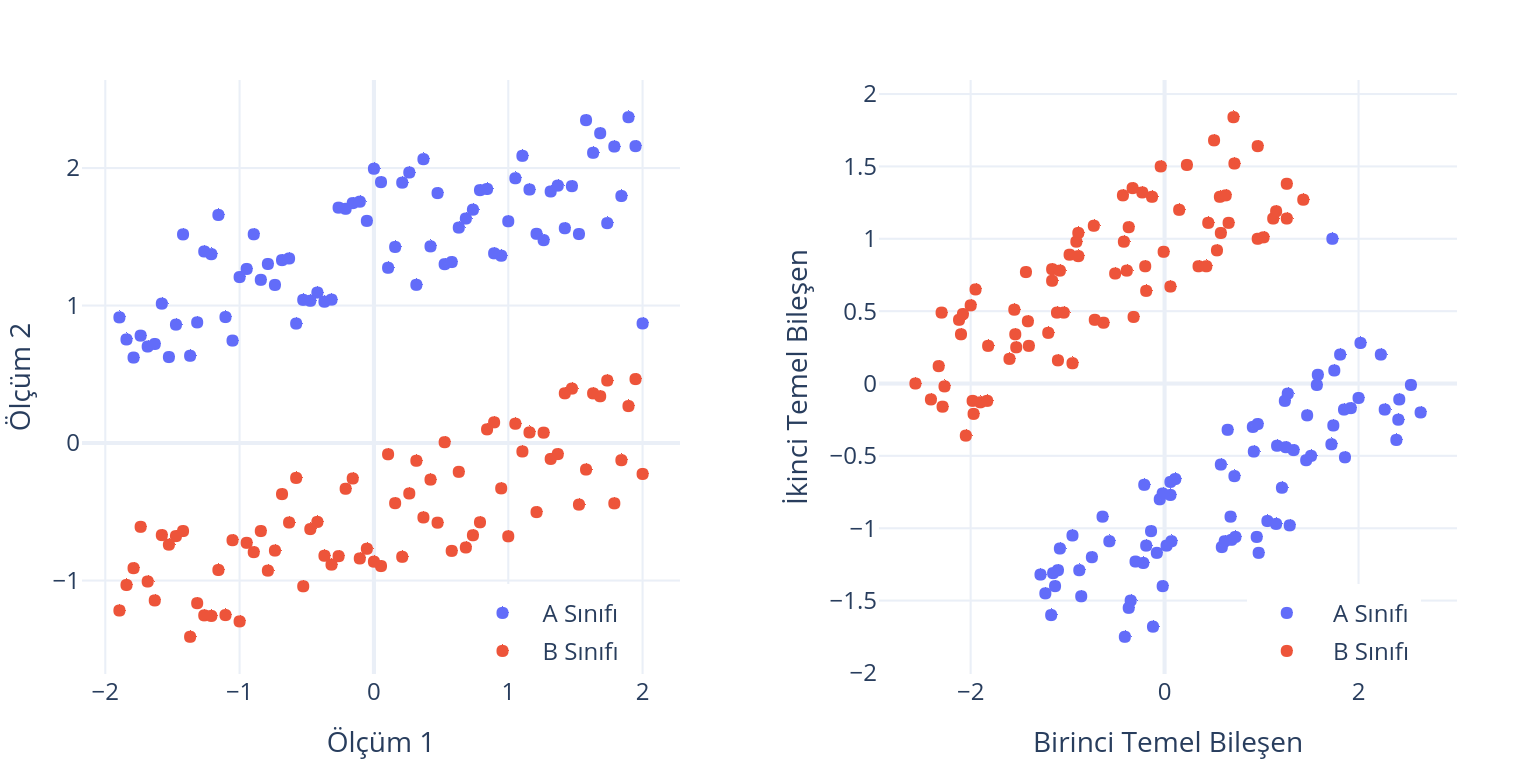
Bu ölçümlere ait TBA sonucu ise sağdaki grafikte verilmiştir. Dikkat edilecek olursa A ve B sınıfı birinci temel bileşen doğrultusunda en yüksek değişintiyi göstermesine rağmen bu doğrultuda ($y$ ekseni sıfır kabul edildiğinde) A ve B sınıflarının ayrıştırılması mümkün değildir. İncelenen veri ikinci temel bileşen doğrultusunda daha az değişinti göstermesine rağmen bu eksenin ayrıştırma gücü daha yüksektir. Örnekte verildiği gibi sınıfların en büyük değişinti eksenleri etrafında dağılmadığı bir sınıflandırma probleminde, boyut indirgeme sonucu elde edilen öznitelikleri sınıflandırma algoritmaları (ne kadar ileri seviye olursa olsun) ayrıştıramayacaktır. Bu gibi durumların önüne geçmek için etiket bilgisinin kullanılabildiği durumlarda toplam değişintinin en büyük olduğu eksen yerine, sınıfların ayrışımını en iyi yapan ekseni bulmaya çalışan Doğrusal Ayrıştırma Analizi (Linear Discriminant Analysis) gibi yöntemler tercih edilebilir.
Yazıda yer alan analizlerin yapıldığı kod parçaları, görseller ve kullanılan veri setlerine cescript_blog_principal_component_analysis GitHub sayfası üzerinden erişilebilir.
Referanslar
- Jolliffe, Ian. Principal component analysis. Springer Berlin Heidelberg, 2011.
- Iris çiçeği veriseti wikipedia sayfası
- Python scikit kütüphanesinde yer alan eğitimcisiz boyut indirgeme yöntemleri