
Nesne tespiti (object detection) karmaşık bir imge içerisinde spesifik/hedeflenen bir nesnenin var olup olmadığını, var ise hangi piksel bölgesi içerisinde yer aldığını belirleme işlemdir. Klasik yöntemlere göre çalışan bilgisayarlı görü uygulamalarında nesne tespiti; imge ön işleme (gri seviye dönüşüm, histogram eşitleme, eşikleme vb.) adımından sonra, nesne tanıma/sınıflandırma (bitki tanıma, yüz tanıma, plaka tanıma) adımından önce yapılan bir işlemdir. Nesne tespiti ile belirli bir nesneyi sınıflandırmak için eğitilmiş bir sistemin girdileri filtrelenerek, sınıflandırma sisteminin girdileri kontrol altına alınır. Bu sayede yüz tanıma için eğitilmiş akıllı bir sistemin yüz olmayan bölgelerde çalışması engellenir ve olası yanlış sınıflandırmaların önüne geçilir.
Nesne tespiti bilgisayarlı görü camiasının uzun süredir üzerinde çalıştığı ve çok başarılı çıktılar ürettiği bir alandır. Bu yazımızda 2001 yılında Paul Viola ve Michael Jones tarafından önerilen ve özellikle yüz tespiti alanında hala sıklıkla tercih edilen Viola-Jones algoritmasını inceleyeceğiz. Viola-Jones algoritması her ne kadar nesne tespiti algoritması olsa da, konuyu yüz tespiti üzerinden anlatmak ve anlamanın daha kolay olacağını düşündüğümden anlatımlarımı bu alt başlık üzerinden yapacağım.
Viola-Jones algoritması bir pencere içerisinde (tipik pencere boyutu 24x24) yer alan piksel bloklarının bir biri ile olan ilşkisini öğrenme prensibi üzerine kurulmuştur. Bu ilişkiyi öğrenebilmek için aşağıda örnekleri gösterilen ve literatürde haar dalgacıkları olarak bilinen öznitelikler ve AdaBoost öğrenme algoritması kullanılmıştır.
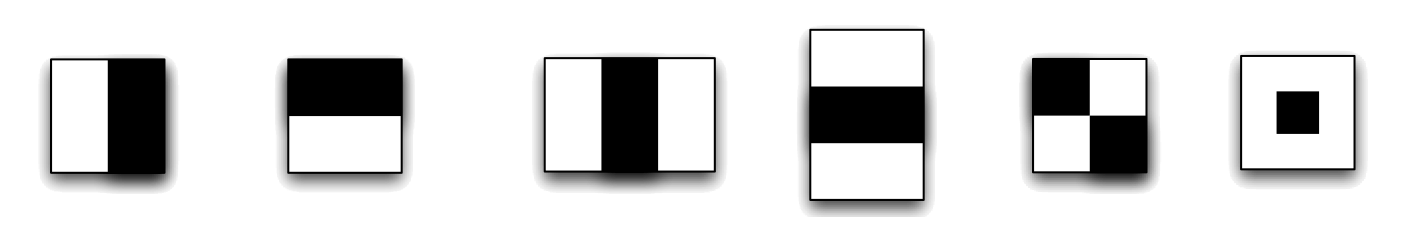
Öznitelik Çıkarımı
Görselleri verilen haar dalgacıklarda siyah pikseller negatif değerleri, beyaz pikseller ise pozitif değerleri göstermek için kullanılmıştır. Evrişim mantığına oldukça benzer şekilde; öznitelikler imge üzerinde gezdirilmekte ve beyaz bölge altında kalan piksellerin toplamı beyaz bölgenin katsayısı ile çarpılmakta, siyah bölge altında kalan piksellerin toplamı ile siyah bölgenin katsayısı çarpılmakta ve ardından bu sayılar toplanmaktadır. $N$ görüntüdeki piksel sayısı, $k$ öznitelikteki toplanacak piksel sayısı olmak üzere bu işlemin karmaşıklığı $O(Nk)$ dır.
Bu işlemin her pikselde yüzlerce öznitelik için yapılması düşünüldüğünde işlemin oldukça uzun sürmesi beklenmektedir. Ancak Viola-Jones tarafından önerilen tümlev imge (integral image) yaklaşımı özniteliklerin hesaplanması karmaşıklığını $k$ öznitelik boyutundan arındırarak, $O(N)$ seviyesine indirmektedir.
Adaboost ile Öğrenme
Adaboost yöntemi ile öğrenme aşamasında ise şu adımlar izlenmektedir: İlk olarak ağırlık vektörü $w$ her bir imgeye eşit ağırlık verilerek ve seçilen sınıflandırıcılar kümesi $h$ boş küme ile ilklenir. Ardından her adımda, özniteliklerin her biri yüz ve yüz olmayan binlerce imgeye (eğitim setine) uygulanır ve imgelerinin bu filtrelere verdiği yanıtlar kaydedilir. Her bir öznitelik için bu yanıtlar kullanılarak eğitim setini en küçük hata ile ayıran bir eşik değeri bulunur ve en küçük hatayı üreten öznitelik seçilir. Seçilen bu öznitelik h kümesine eklenir. Son aşamada belirlenen sınıflandırıcının çıktıları kullanılarak doğru sınıflandırılan örneklerin ağırlığı azaltılır, yanlış sınıflandırılan örneklerin ağırlığı artırılır. Ardından yeni ağırlıklar ile yeni bir öznitelik belirleme işlemine geçilir. Bu işlem belirli sayıda ($T$ tane) sınıflandırıcı belirlenene kadar devam edilir.
Algoritmanın çalışma prensibine ilişkin sözde kod aşağıdaki tabloda verilmiştir.
-
Eğitim setinde yer alan her olumlu örnek $x_i$ için $y_i=1$, her olumsuz örnek $x_i$ için $y_i=0$ etiketi atanır. $N$ olumlu ve $M$ olumsuz örnek sayısı olmak üzere, ağırlık vektörü $w_{1,i} = {\frac{1}{2N},\frac{1}{2M}}$ her bir imgeye eşit ağırlık verilerek ilklenir.
-
Her iterasyon $t = 1:T$ Ağırlıklar olasılık dağılımı olacak şekilde normalize edilir \(w_{t,i} = \frac{w_{t,i}}{\sum_{j=1}^{M+N} w_{t,j}}\)
-
Her $h_j$ özniteliğini eğitim setine uygula ve kalan hatayı \(\epsilon_j = \sum_i w_i\lVert h_j(x_i) - y_i\rVert\) hesapla.
-
En küçük hatayı $\epsilon_t$ veren $h_t$ özniteliğini belirle. Doğru sınıflandırılan her örnek için $\beta_i=\left({\frac{\epsilon_t}{1-\epsilon_t}}\right)$ olmak üzere \(w_{t+1,i}=w_{t,i}\beta_i\)
-
Nihai sınıflandırıcıyı $\alpha_t = -\log{\beta_t}$ olmak üzere \(h(x)= \begin{cases} 1, & \sum_{t=1}^{T}\alpha_t h_t(x) \geq \frac{1}{2}\sum_{t=1}^{T}\alpha_t \\ 0, & \text{otherwise} \end{cases}\) olarak belirle.
Belirli sayıda öznitelik belirlendikten sonra sınıflandırıcı çalıştırılarak eğitim kümesi sınıflandırılmaktadır. Bu sınıflandırma işleminden sonra yüz olmadığına kanaat getirilen eğitim örnekleri atılarak kalan eğitim kümesi ile öğrenme işlemine devam edilir. Bu kaskat yapı sayesinde hem yüz olmadığı kolaylıkla anlaşılan örneklerin süreci yavaşlatmasının önüne geçilir hem de geriye kalan hatalı örneklerin ağırlığı artırıldığından daha yetkin bir sınıflandırıcı öğrenilmesi sağlanır.
Test Aşaması
Test aşamasında ise imge üzerinde gezilerek öğrenilen bu öznitelik setlerinin sonuçları hesaplanır. Her kaskat sonrası elde edilen değerler öğrenilmiş değerler ile kıyaslanarak incelenen alt pencerenin yüz olup olmadığına karar verilir. Eğer herhangi bir aşamada alt pencerenin yüz içermediğine karar verilirse ileri aşamada yer alan öznitelikler incelenmeden bir sonraki alt pencereye geçilir.
Aşağıda IMLAB görüntü işleme kütüphanesi kullanılarak Viola-Jones özniteliklerinin iki farklı test imgesi üzerinde nasıl çalıştığı gösterilmiştir. İmge üzerinde kayan pencere yüz olup olmadığı test edilen pencereyi, pencerenin rengi ise (kırmızıdan yeşile) ise kaskat sınıflandırıcının kaçıncı kaskatta olduğunu göstermektedir. Pencere içerisinde beliren dikdörtgenler ise testte kullanılan haar özniteliklerini göstermektedir. Görselliği iyileştirmek amacı ile negatif katsayılı öznitelikler siyah, pozitif katsayılı öznitelikler beyaz ile renklendirilmiştir.
| Viola Jones Başarılı Tespit Adımları | Viola Jones Başarısız Tespit Adımları |
|---|---|
 |
 |
Videodan yüz olmayan bölgelerin bir kaç kaskat incelemesinden sonra elenirken, yüz olma potansiyeli bulunan bölgelerin daha detaylı (daha fazla sayıda haar özniteliği ile) incelendiği görülmektedir. Bu kaskat yapı Viola-Jones algoritmasının performansını artıran önemli bir bileşendir.
Bu yazımızda Viola-Jones algoritmasını öğrenilmiş bir öznitelik havuzunu kullanarak gerçeklemeye çalışacağız. Kullanacağımız öznitelik seti OpenCV topluluğu tarafından yüz tespiti için eğitilen ve haarcascade_frontalface_alt ismi ile paylaşılan haar öznitelik seti olacak ve kodlamada IMLAB görüntü işleme kütüphanesini kullanacağız.
// load the test sample
matrix_t *test = imread("..//data//faces//oscar.bmp");
// convert it to grayscale
matrix_t *gray = matrix_create(uint8_t, rows(test), cols(test), 1);
rgb2gray(test, gray);
// load the object model
struct haar_t *model = haar_read("../data/cascades/haarcascade_frontalface_alt.json");
// do the detection
vector_t *detections = haar_detector(gray, model, 20, 500, 1.15, 1.5f);
// merge the overlapping rectangles
detections = rectangle_merge(detections, 0.3, 1);
// draw the detections
printf("Drawing the %d detected objects...\n", length(detections));
struct rectangle_t *obj = vdata(detections, 0);
for(int i = 0; i < length(detections); i++)
{
printf("obj[%03d]: %d %d %d %d\n", i, obj[i].x, obj[i].y, obj[i].width, obj[i].height);
// set the thickness of the detected object
uint32_t thickness = max(1, sqrt(obj[i].width * obj[i].height) / 20);
draw_rectangle(test, obj[i], RGB(50, 140, 100), 2 * thickness + 1);
draw_rectangle(test, obj[i], RGB(80, 250, 255), thickness);
}
// write the marked objects as image
imwrite(test, "detected_objects.bmp");
// clear the allocations
matrix_free(&test);
matrix_free(&gray);
vector_free(&detections);
Verilen kodda ilk olarak test için kullanılacak görüntü okunmakta ve gri seviyeye çevrilmektedir. Ardından IMLAB kütüphanesinde yer alan ve Viola-Jones algoritmasında kullanılmak üzere eğitilen haar özniteliklerini saklayan haar_t modeli haar_read fonksiyonu yardımı ile içeri aktarılmıştır. İçeri aktarılan öznitelikler haar_detector fonksiyonu ile istenilen nesnelerin tespit edilmesi sağlanmıştır.haar_detector fonksiyonunun ilk parametresi testpitin yapılacağı imge, ikinci parametresi ise kullanılacak haar modelidir. Fonksiyonun üçüncü parametresi tespit edilecek en küçük, dördüncü parametresi ise en büyük nesne boyutunu piksel cinsinden ifade etmektedir. Fonksiyonun beşinci parametresi en küçük nesne ile en küçük nesne arasında arama yapılırken kullanılacak ölçekleme katsayısını göstermektedir. Fonksiyonun son parametresi ise pencere kaydırma adımlarını göstermektedir.
Aşağıda kodun örnek bir imge üzerindeki çıktısı verilmiştir. Görüldüğü üzere oldukça karmaşık bir imgede dahi algoritma çok az sayıda hatalı tespit üretmektedir.

Referanslar
- Viola, Paul, and Michael Jones. “Rapid object detection using a boosted cascade of simple features.” Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. Vol. 1. IEEE, 2001.