
Regresyon (bağlanım) analizi, bilinen değişkenler baz alınarak bilinmeyen değişkenlerin modellenmesi / tahmin edilmesi işlemidir. İfadenin daha anlaşılır olması için örnek verecek olursak; doktorlar uyguladıkları tetkikleri (tansiyon, şeker, demir miktarı, vs.) baz alarak bir hastalığın olup olmayacağına karar verebilirler veya emlakçı bir evin fiyatını oda sayısı, konumu, alanı gibi bilgileri baz alarak tahmin edebilir. Bu işlemin insanlar tarafından yapılabilirliği, bilinen değişkenlerin artması (baz noktaları) ile ters orantılıdır. Doktor örneğine geri dönecek olursak, karmaşık bir hastalığın tespiti için yapılan analizlerin sayısı arttıkça, doktorun bu sonuçları değerlendirme süresi de artacaktır.
Bu yazımızın konusu olan Lojistik Regresyon, bu modellemenin bilgisayarlar ortamında otomatik yapılmasını sağlayan bir yöntemdir. Yöntem baz noktalarını bildiğinde, bilinmeyen bir olay hakkında çıkarımda bulunduğundan aslında bir makine öğrenmesi / yapay zeka örneğidir. Yöntemin detaylarına girmeden önce temel kavramları anlamaya çalışalım.
Makine öğrenmesi yöntemlerinin çoğunun çalışması için bir eğiticiye ihtiyaç vardır. Buradaki eğitici, elimizde bulunan baz noktalarına karşı düşen gerçek değeri bize sağlayan kişidir. Elimizde bu değerlerden ne kadar çok varsa, makine öğrenmesi o kadar başarılı olacaktır. $N$ elde bulunan veri sayısını, $x_n$ $n$. veriye ait baz değerlerini ($m$ tane) ve $y_n \in \{-1,+1\}$ bu veriye karşı düşen gerçek değeri (etiketi) (hasta:1, sağlam:-1; pahalı:1, ucuz:-1) göstermek üzere, doğrusal öğrenme problemi şu şekilde modellenir:
\[s=w^T x = w^1x^1+w^2x^2+...+w^mx^m\]Burada $w^T$ her bir baz noktasına karşı düşen ağırlıkları içeren ağırlık vektörü, $s$ ise tahmin edilen değerdir. Öğrenme ise eğitici tarafından sağlanan etiketler ($y_n$) ile tahmin edilen etiketler ($s_n$) arasındaki uzaklığı en aza indirecek ağırlıkları ($w$) bulma işlemidir.
Bu tip bir modellemedeki temel sorun, tahmin edilen değerin bir sınırının olmaması ve büyük ağırlık değerleri için tahmin edilen etiketin hızla artmasıdır. Lojistik regresyon bu problemi çözmek için önerilen ve günümüzde de sıklıkla kullanılan bir öğrenme yöntemidir. Yöntem tahmin edilen etiket değerini bir lojistik fonksiyonundan ($\theta(s)$) geçirerek çıkışın sınırlı olmasını garanti altına alır. Regresyona adını veren lojistik (logit) fonksiyonu şu şekilde tanımlıdır: \(\theta(s) = \frac{1}{1+e^{-s}}.\) Bu fonksiyonun farklı $s$ değerleri için değerleri, doğrusal fonksiyon (yeşil) ile karşılaştırmalı olarak grafikte gösterilmiştir.
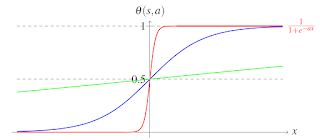
Böyle bir tanımalama sonrası çıkışın $\left[0,1\right]$ aralığında olması sağlanır ve çıkışa olasılık yaklaşımı yapılabilir. Örneğin doktor probleminde algoritmanın çıkışı 0.8 ise gelen hastaya %80 olasılıkla hasta (1), %20 olasılıkla sağlam (-1) teşhisi konulabilir. Bu söylemi matematiksel olarak ifade etmek istersek
\[P(y=1 \lvert x) = \theta(s) = \frac{1}{1+e^{-w^T x}}, P(y=-1 \lvert x) = 1-\theta(s) = \frac{1}{1+e^{w^T x}}\]yazabiliriz (İkinci eşitlik olasılıkların toplamı bir olduğu bilgisi kullanılarak yazıldı). Lojistik fonksiyonunun tanımı gereği $\theta(s)=1-\theta(-s)$ olduğundan yukarıdaki eşitlikler tek bir ifadede birleştirilerek
\[P(y\lvert x) = \frac{1}{1+e^{-y w^\intercal x}}\]elde edilir. Burada $y=\pm 1$ değerinin lojistik fonksiyonun içerisine girdiğini ve ifadenin $y=1$ için $P(y=1 \lvert x)$, $y=-1$ için $P(y=-1 \lvert x)$ eşitliklerine eşit olduğuna dikkat edilmelidir.
Dikkat edilecek en önemli nokta ise aradığımız ağırlıkların $P(y_n \lvert x_n)$ olasılığını mümkün olduğunca bire (kesin olay) yaklaştırması gerektiğidir. Bulunacak ağırlık değerlerinin elimizdeki tüm eğitim verileri $n=1,2,\dots,N$ için bu olasılığı bire yaklaştırmasını istediğimizden
\[L(x,y \lvert w) = \Pi_{n=1}^N P(y \lvert x) = \Pi_{n=1}^N \frac{1}{1+e^{-yw^T x}}\]tanımı yaparak olabilirlik göstergesi $L(x,y \lvert w)$ tek bir fonksiyonu en büyüklemeye çalışabiliriz. Burada $P(y_n \lvert x_n)$’ lerin bire yaklaması ile $L(x,y \lvert w)$ nin arttığına dikkat edilmelidir. Burada olabilirlik fonksiyonunu doğrudan kullanmak yerine logaritmasını kullanmak işlem kolaylığı sağladığından ve logaritmanın monoton artan bir fonksiyon olmasından dolayı $L(x,y \lvert w)$’ yi en büyüklemek ile $log(L(x,y \lvert w) )$’ i en büyüklemek arasında bir fark olmadığından logaritmik olabilirlik fonksiyonu kullanılmıştır.
Logaritma işlemi sonrası çarpma sembolü toplama sembolüne dönüşeceğinden yeni olabilirlik fonksiyonu
\[L(x,y \lvert w) = \sum_{n=1}^N \log\left ({1}/{1+e^{-yw^\intercal x}}\right )\]olacaktır. Yapılacak son bir değişiklik ise logaritma içerisindeki bölüm ifadesini kaldırarak, fonksiyonu en büyüklemek yerine, yeni fonksiyonu $E(x,y \lvert w)$ en küçüklemeye çalışmak olacaktır.
\[E(x,y \lvert w) = \sum_{n=1}^N \log\left ({1+e^{-yw^\intercal x}}\right )\]Burada $E$ fonksiyonu için kapalı biçim bir çözüm bulunmadığından en küçükleme iteratif olarak yapılmalıdır. Bu yazımda $E$ fonksiyonu en küçüklemek için en kolay yöntemlerden biri olan gradyan iniş yöntemini tercih ettim.
Gradyan İniş Yöntemi
Bu yöntem herhangi bir fonksiyonun yerel en küçük noktasının o fonksiyonun o noktadaki gradyanı tersi yönüne hareket edilerek bulunacağı fikrine dayanmaktadır. Bu fikri bir görsel üzerinde gösterdiğimizde çok daha anlaşılır olacaktır.

Yukarıda verilen grafikte bir $P(x,w)$ fonksiyonu gösterilmiştir. Bu fonksiyon quadratik bir fonksiyon olduğu için en küçük değeri;
\[\frac{\partial P}{\partial w} = 0\]eşitliğini sağlayan $w$ değerinde alacaktır. Bu değer grafikten de görüldüğü üzere $w=w_b$ değeridir. Peki $w=w_a$ gibi rastgele bir $w$ değerinden başlayarak $w=w_b$ değerini bulabilir miyiz? Grafikten de görüldüğü üzere, $w=w_a$ olduğunda $P(x,w_a)$ noktasının gradyanı $\nabla_w P(x,w_a)$ yönü negatif değerli olmaktadır. Bu durumda gradyanın tersi yönünde ilerlenmesi durumunda $a=w_b$ değerine yaklaşılacaktır. Bu kurala göre adımlar attığımızda, her adımda fonksiyonun tepe noktasından en küçük noktasına inişe geçeceğimizden bu yöntem Gradyan İniş Yöntemi olarak adlandırılmaktadır. Matematiksel olarak gradyan iniş yöntemi;
\[w_k^{(t+1)}=w_k^{(t)}-\alpha \nabla_w P(x,w)\]$w_k=0$ ilk değerinden başlayarak iteratif olarak fonksiyonu en küçükleyecek ağırlıkları bulmaya çalışan bir yöntemdir. Burada $\alpha$ gradyan inişinin hızının ayarlanması için kullanılan sabit bir terimdir. Özellikle iterasyonun başlarında en küçük noktaya hızlı varmak için büyük bir $\alpha$ değeri seçilirken, iterasyonun ilerleyen adımlarında $w=w_b$ kritik noktasını geçmemek için kısılır. $\nabla_w P(x,w)$ ise gradyan operatörüdür.
En küçüklemeye çalıştığımız fonksiyon için gradyan \(\nabla_w E = -\sum_{n=1}^N yx\log\left ({1+e^{-yw^T x}}\right)\) şeklindedir. Yöntem her iterasyonda bir önceki ağırlıklara $\gamma$ gibi küçük bir ağırlıkla çarparak gradyan değerini eklemektedir.
Bu kadar matematikten sonra kodlama kısmına geçebiliriz. Lojistik regresyon eğitimi için yazılan kod aşağıda verilmiştir.
void logistic_regresyon(double *data, int *label, double *weights,int Nsample,int Nlength)
{
// the learning rate
double epsil = 0.001;
double gamma = 0.001;
double diffe = 0;
int iter_max = 1000;
int iter = 0, i,j,k;
// make sure the initial weights are zero
memset(weights,0,Nlength*sizeof(double));
while (iter < iter_max) {
diffe = 0;
// update each weight
for (k=0; k < Nlength; k++) {
double gradient = 0;
for (i=0; i < Nsample; i++) {
double z_i = 0;
for (j=0; j < Nlength; j++) {
z_i += weights[j] * data[j+Nlength*i];
}
gradient += label[i] * data[k+Nlength*i] * sigmoid(-label[i] * z_i);
}
weights[k] += gamma * gradient;
diffe += fabs(gamma * gradient);
}
iter += 1;
if (diffe < epsil) {iter = iter_max;}
}
}
Umulanın aksine yazının en kolay bölümü kodlama kısmı sanırım. Yukarıda anlatımını yaptığımız tüm işlemler ağırlıkların bulunmasını sağlayacak gradyan iniş yöntemi için bir ifade bulmaktı. Bu ifade türetildikten sonra kod içerisinde her bir örnek için gradyan hesabı yapılmış ve gradyan iniş yöntemi gereği ağırlıklar bu gradyan kullanarak güncellenmiştir. Yöntem iteratif bir yöntem olduğundan iterasyonun durması için ağırlık değişiminin epsil=0.001 gibi küçük bir değerin altında olması veya iterasyon sayısının 1000 iterasyondan az olması koşulları eklenmiştir.
Ağırlıkların bulunmasının ardından verinin sınıflandırılması içinse aşağıdaki kod yazılmıştır.
void predict(double *data, double *weights, int *label, int Ntest, int Nlength)
{
double prediction = 0;
double summation = 0;
int k,i;
for (k=0; k < Ntest; k++)
{
summation = 0;
for (i=0; i < Nlength; i++)
{
summation += weights[i] * data[i+Nlength*k];
}
prediction = sigmoid(summation);
if (prediction > 0.5) { label[k] = +1; }
else { label[k] = -1; }
}
}
Yazıda da belirtildiği üzere sınıflandırma için bulunan ağırlıklar kullanılarak $P(y=1 \lvert x) = {1}/{1+e^{-w^T x}}$ olasılığı bulunmuştur. Bu olasılık 0.5 den büyükse, test edilen $x$ verisi $y=1$, küçük ise $y=-1$ olarak etiketlenmiştir.
Diğer yazılarımdan farklı olarak bu yazı için örnek kısmını bir sonraki yazıma bırakıyorum. Bir sonraki yazım uzun zamandır devam edemediğim sudoku çözücü uygulaması için de en kritik adım olan rakam tanıma üzerine olacak.
Referanslar
- Abaci, Bahri, and Tayfun Akgul. “Matching caricatures to photographs.” Signal, Image and Video Processing 9.1 (2015): 295-303.