
Optik karakter tanıma (OCR) sayısal imgeler üzerinde bulunan rakam, harf ve noktalama işaretlerinin tanınarak kodlanmış metinlere dönüştürülmesi işlemidir. İlk kullanım amaçlarından biri görme engellilerin okumasına yardımcı olmak olan sistem, yüz yıllık geçmişi ile, günümüzde yazılı belgelerin arşivlenmesi, pasaport/kimlik doğrulama, iş kartı tarama, postaların otomatik yönlendirilmesi gibi pek çok alanda kullanılmaktadır. Sistemin ileride planlanan bir kullanımı ise çekilen fotoğraflarda bulunan metinlerin algılanarak, fotoğrafların içerikleri hakkında daha fazla bilgi sahibi olmak ve fotoğraf aramalarını daha kullanıcı dostu bir hale taşımaktır.
Bu yazımızın konusu olan rakam tanıma ise optik karakter tanımanın küçük ve çözülmüşe yakın bir alt dalıdır. Yazımızda kullanacağımız makine öğrenmesi yöntemi bir önceki yazıda girişini yaptığımız lojistik regresyon analizi olacak. Bir önceki yazıyı okumamış olanlar devam etmeden önce bu bağlantıya tıklayarak analiz hakkında detaylı bilgiye sahip olabilirler.
Lojistik regresyon ile ilgili temel kavramları anladıktan sonra rakam tanıma için aşağıdaki iki temel sorunun kafanızı kurcalaması gerekiyor.
1. Rakam tanıma için kullanılacak bilinen baz vektörleri nelerdir?
2. Analiz sadece iki sınıfa (+1,-1) ayırabiliyorsa, 10 sınıfı (0,1,...,9) nasıl ayırabiliriz?
Sorulardan ilkinin standart bir cevabı bulunmamakta. Bazı örnekler baz olarak sayılarda bulunan çizgi, eğri, yuvarlak sayısını kullanırken bazı uygulamalar pikseller üzerine uygulanan dönüşümleri (Gabor dönüşümü) kullanaktadır. Biz bu yazımızda en kolay baz vektörlerden biri olan piksel yoğunluklarını kullanacağız. Daha açık konuşacak olursak baz vektörümüz rakam imgesinin ilk (0,0) noktasındaki piksel değeri ile başlayıp son (M,N) noktasındaki piksel değeri ile bitecek. Yazımızda kullanacağımız veritabanı 8x8 imgelerden oluştuğundan baz vektörlerimiz 64 uzunluklu olacak.
Kafamıza takılan ikinci sorunun çok daha standart bir cevabı bulunmakta. Bu çalışmada ve hemen hemen tüm makine öğrenmesi çalışmalarında karşılaşılan ikili sınıflandırıcı kullanarak çok sınıflı öğrenme problemi, ikili sınıflandırıcıların “bire karşı hepsi” yöntemi ile birleştirilerek kullanılması ile çözülür. Yöntemi aşağıdaki 3 sınıflı kare, yuvarlak ve artı, bir örnek üzerinden anlamaya çalışalım.
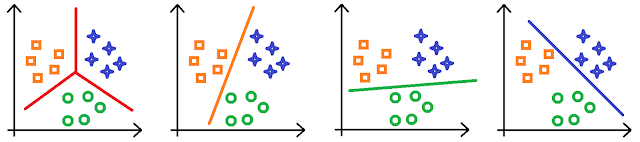
İlk resim bulmamız gereken ideal ayırtaçları göstermekte. İki sınıflı doğrusal sınıflandırıcılar sadece doğrular çizebildiğinden tek bir sınıflandırıcı ile ayrım yapmak imkansızdır. Bire karşı hepsi yöntemi bu ayrımı üç farklı sınıflandırıcı eğiterek yapmayı öneriyor.
Sınıflandırıcının adından da anlaşılacağı üzere sınıflandırma seçilen bir sınıfa karşı diğer sınıfları tek bir sınıfmış gibi düşünerek, problemi ikili sınıflandırma problemine dönüştürüyor. Yani tasarlanan üç sınıflandırıcıdan ilk sınıflandırıcı (2. şekil) kareleri kare ve yuvarlak grubundan ayırmak için, ikinci sınıflandırıcı yuvarlakları kare ve artı grubundan ve son sınıflandırıcı ise artıları kare ve yuvarlak grubundan ayıracak şekilde eğitiliyor.
Sınıflandırma aşamasında, sınıflandırıcımızın +1 grubuna ait olma olasılığını verdiğini bildiğimizden seçilen bir test noktası, eğitimi yapılan üç sınıflandırıcı ile test edilerek kare, yuvarlak ve artı gruplarına ait olma olasılıkları hesaplanıyor. Seçilen nesnenin ait olduğu grup ise bu olasıkların en yüksek olduğu grup olarak belirleniyor.
Bire karşı hepsi mantığını anladıktan sonra yazılan kod kısmına gelecek olursak. Bir önceki yazımızda ikili bir sınıflandırıcıyı kodladığımızdan bu yazımızda sadece ikili sınıflandırıcın 10 farklı sınıf için çağrılmasına ait kodlamayı yapmamız yeterli.
void coklu_egitim(double *data, int *label, double *weights[],int Nsample,int Nlength, int Nclass)
{
// Her sınıf için logistic regresyon eğit
// 10 sınıf için 10 ağırlık olacak
int i,j;
int *binary_label = new int [Nsample];
for (i=0; i < Nclass; i++)
{
// tüm etiketleri -1 yap
memset(binary_label,-1,Nsample*sizeof(int));
for (j=0; j < Nsample; j++)
{
// i. sınıf için eğitim yapılacağından
// etiket i ise +1, değilse -1 olsun
if(label[j]==i) { binary_label[j] = 1; }
}
// i. sınıf için eğitim yap ve ağırlıkları sakla
logistic_regresyon(data, binary_label, weights[i], Nsample,Nlength);
}
}
Kod içerisinde lojistik regresyon fonksiyonu çağrılmadan önce eğitim yapılacak olan sınıfa +1, diğer sınıfların tamamına ise -1 etiketleri atanmaktadır. Bir önceki kodlamadan farklı olarak lojistik regresyon fonksiyonu 10 kez çağrılacağından tek bir ağırlık vektörü yerine 10 elemanlı bir ağırlık vektörü (matrisi) kullanıldığına dikkat edilmelidir. Tahmin kısmında da yukarıda vurhulandığı üzere bire karşı hepsi mantığı kodlanmıştır.
void coklu_tahmin(double *data, double *weights[],int *label, int Ntest,int Nlength, int Nclass)
{
double prediction = 0, max_prediction = 0;
double summation = 0;
int k,i,j;
// herkesi test et
for (k=0; k < Ntest; k++)
{
// her sınıf için kontrol et
for (i=0; i < Nclass; i++)
{
summation = 0;
for (j=0; j < Nlength; j++)
{
summation += weights[i][j] * data[j+Nlength*k];
}
prediction = sigmoid(summation);
if (prediction > max_prediction) { max_prediction = prediction; label[k] = i; }
}
max_prediction = 0;
}
}
i üzerinden dönen herbir döngüde k. kişinin i. sınıfa ait olma olasılığı hesaplanmış ve k. kişinin etiketi tahmin edilen sınıf olasılıklarına göre güncellenmiştir.
Çok sınıflı sınıflandırma ile ilgili yukarıdaki bilgileri bildikten sonra yazımızın konusu olan rakam tanıma problemine başlayabiliriz. Bu yazı için hazırladığım örnek Boğaziçi Üniversitesinde Ethem Alpaydın tarafından hazırlanan OptDigits rakam veritabanı.
Veritabanı 43 kişinin el yazısı kullanılarak oluşturulan ve her bir sınıf için (0-9) yaklaşık 380 eğitim, 180 test imgesi içermekte. Veri tabanında yer alan orjinal imgeler 32x32 boyutlu ve siyah-beyazdır. Buna ek olarak bu imgelerin makine öğrenmesinde kullanılmak üzere 8x8 boyuta indirgenmiş versiyonları da veritabanında yer almaktadır.
Bu indirgeme yapılırken 32x32 boyutlu imge 4x4 büyüklükte örtüşmeyen bloklara ayrılmış ve yeni imgedeki her bir piksel bu blokların içerisinde kalan piksellerin toplamı ile bulunmuştur. Yani 8x8 boyutlu görüntüler en büyük değeri 16, en küçük değeri 0 olan gri seviye imgelerdir. Veritabanının görüntüsü aşağıda verilmiştir.

İmgeler veritabanında herbir satırda bir imgenin piksel (8x8->1x64 vektör) verisi ve etiketi (1x1 vektör) olacak şekilde 1x65 uzunluklu vektörler ile saklanmaktadır. Yani dosyadan veriler okunurken ilk 64 değer data matrisine, son değer ise etiket matrisine eklenmelidir.
Veritabanında yer alan imgeler eğitim ve test seti olarak ayrıldığından ben de bu ayrıma sadık kalarak eğitimi 3823 eğitim verisi üzerinde, testi ise 1797 test imgesi üzerinde yaptım. Doğrusal bir öğrenme yapmanın sanırım en büyük avantajı olarakta 1797 rakamın sınıflandırılması <100ms gibi kısa bir sürede tamamlandı. Test imgeleri üzerinde aldığım toplam başarı %92.88, diğer bir deyişle 1797 imge test edilirken 128 tanesi hatalı sınıflandırıldı. Bu hatalardan 39 tanesi 8 rakamının sınıflandırılması sırasında oluştu ve algoritma en çok 8 ile 2 yi ayırmakta zorlandı.
Referanslar
-
C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their Applications to Handwritten Digit Recognition, MSc Thesis, Institute of Graduate Studies in Science and Engineering, Bogazici University.
-
Optical Recognition of Handwritten Digits Data Set LINK