
Kümeleme (öbekleme) bir veri setinde, benzer özellik gösteren elemanların bir grup altında toplanması işlemidir. Böylelikle çok büyük girdiler içeren bir veri seti, çok daha düşük sayıda grupla ifade edilebilmektedir. Kümelemenin makine öğrenmesi / veri madenciliği alanında kullanımı büyük ve etiketsiz veri yığınlarının otomatik olarak gruplara ayrılmasını amaçlamaktadır. Böylelikle etiketsiz büyük bir veri yığını kabaca etiketlenmiş olur ve bu etiketler kullanılarak arama algoritmaları hızlandırılabilir, veri hakkında özet bilgi çıkarılabilir veya temiz etiketleme işlemi için gereken süre azaltılabilir.
Günümüzde yaygın kullanım alanlarından biri de sosyal ağlarda benzer davranışlar sergileyen kişi veya grupların bir araya öbeklenerek, bu öbeklere yönelik reklamların planlanması, öbeklerin davranış analizleri ile sosyal medya trendlerinin takibi ve bu öbeklerin birbirlerine önerilmesi ile sosyal bağın artırılması sağlanmaktadır.
Öbeklemenin görüntü işleme alanında ise imge bölütleme, nesne tanıma ve renk indirgeme gibi kullanım alanları vardır. Öbekleme işlemi giriş verilerinde etikete ihtiyaç duymadığından bir eğiticisiz öğrenme yöntemidir ve literatürde farklı kullanım alanlarına yönelik önerilmiş çok sayıda kümeleme algoritması (K-means, Fuzzy C-means,Hierarchical clustering,Mixture of Gaussians) bulunmaktadır. Bu yazımızın konusu olan K-ortalamalar (K-means) algoritması gerek basitliği gerekse de ürettiği başarılı sonuçlar nedeniyle günümüzde en yaygın kullanılan 10 veri madenciliği algoritması arasındadır [1]. Algoritma veriyi iteratif şekilde analiz ederek N örnekten oluşan bir veriyi önceden bilinen K (öbek sayısı) kadar kümeye bölmeye çalışır. Bölme işleminin ardından N örneğin herbiri, kendisine en yakın kümenin etiketi ile etiketlenir. Algoritmanın adımları beş adımda özetlenebilir:
1. Küme merkezlerini rastgele ata
2. Herbir örneğe kendisine en yakın kümenin etiketini ata
3. Aynı etiketli örneklerin ortalamasını kullanarak yeni küme merkezlerini bul
4. İterasyon sonlanana kadar 2-3 işlemlerini tekrarla
5. Bulunan küme merkezlerini döndür
Yukarıda algoritmik olarak verilen işlemleri örnek bir imge üzerinde anlamaya çalışalım. Aşağıda verilen örnek veri 150 noktanın x ve y koordinatlarını içermektedir. Eğiticisiz öğrenme gereği etiket bilgisi kullanılmadığından algoritmanın başlangıcında hiçbir örnek bir gruba ait değildir ve bu yüzden siyah renkle gösterilmişlerdir.
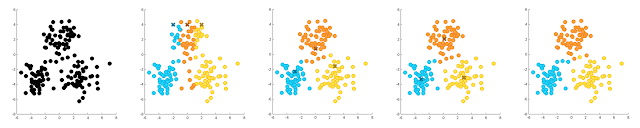
K-ortalamalar (K-means) algoritması ilk olarak rastgele grup merkezleri tahmin ederek işleme başlar. Burada grup merkezleri x işareti ile gösterilmiştir. Mekezler tahmin edildikten sonra herbir örneğe ikinci resimde gösterildiği gibi kendisine en yakın grubun etiketi atanır. Bir sonraki adımda (üçüncü resim) örneklerin atanan etiket bilgisi kullanılarak grup merkezleri tahmin edilmeye çalışılır. Bunun için tüm mavi noktaların ortalaması alınarak mavi kümesinin merkezi, turuncu gruba ait elemanların ortalaması alınarak turuncu grubun merkezi ve sarı gruba ait elemanların ortalaması alınarak sarı kümesinin merkezi bulunur. Bu hesaplamanın ardından yeni merkez noktaları kullanılarak örneklerin ait olduğu sınıflar tekrar hesaplanır. Benzer bir hesaplama tekrar edildiğinde sonuç dördüncü resimdeki gibi görülmektedir. Beşinci imge ise noktaların gerçek etiket değerlerini göstermektedir. Dikkat edilecek olursa noktalar %95 üzerinde doğru tahmin edilmiştir.
Burada akla gelecek bir soru iterasyonun ne zaman duracağıdır. Resimde küme merkezlerine dikkat edilecek olursa ikinci adımdan üçüncü adıma geçerken küme merkezlerinin yer değişimi fazla iken bir sonraki iterasyonda merkezlerin değişiminin azaldığı görülür. Uygulamada genellikle yer değişimindeki bu azalma bilgisi kullanılır ve merkezlerin yer değişimi belirli bir eşiğin altına düştüğünde iterasyon sonlandırılır. Yazımızın bu kısmına kadar olan kısmını kodlamaya başlayalım.
double* kmeans(double *data, int K, int L, int N)
{
/* Degisken Tanimlamalarini Yap */
/* Veri matrisine bakarak centroidleri ata*/
intialCentroids(data, Ocentroids, K, L, N);
while (fark > 0.02)
{
/* Data daki her elemanı bir sinifa ata */
findMinDist(data, Ocentroids, minDistKpp, minDistIdx, K, L, N);
/* Herbir sinifin kendi icinde ortalamasini bul */
updateCenters(data, Ncentroids, minDistKpp, minDistIdx, K, L, N);
/* Güncelleme sonrası merkez değişimlerini hesapla */
fark = 0;
for(k=0; k < K; k++)
{
for(l=0; l < L; l++)
{
fark += fabs(Ncentroids[l+k*L] - Ocentroids[l+k*L]);
}
}
memcpy(Ocentroids,Ncentroids,K*L*sizeof(double));
}
return Ocentroids;
}
Kodumuzda üç önemli değişken ve üç önemli fonksiyon bulunmakta. data değişkeni N örneğe ait L uzunluklu verileri tutan değişkenimiz. Ocentroids ve Ncentroids değişkenleri ise k-ortalama sonucunda bulunan küme merkezlerini tutmak için kullanılan değişkenlerdir. Herbiri L uzunluklu K sınıf olduğundan iki değişkenin de boyutu KxL boyutundadır ve Ocentroids güncelleme
öncesi ortalama noktaları, Ncentroids ise güncelleme sonrası ortalama noktalarını tutmak için kullanılmıştır. Kod dikkatli incelenecek olursa intialCentroids fonksiyonu algoritma kısmında verilen birinci adımı, findMinDist ikinci adımı ve updateCenters ise üçüncü adımı ve while (fark > 0.02) döngüsü de dördüncü adımı gerçekleştirmektedir.
Fonksiyonları detayla inceleyecek olursak, findMinDist fonksiyonu veriyi ve eski merkez noktalarını alarak herbir veri noktası
için en yakın merkez noktasını bulmakta ve bunu minDistIdx dizisinde, en yakın merkez noktasına olan uzaklıkları ise minDistKpp içerisinde saklamaktadır. Çalışmada uzaklık ölçüsü için genelde tercih
edilen Öklid uzaklığı kullanılmıştır.
void findMinDist(double *data, double *centroids, double *minDistKpp, int *minDistIdx, int K, int L, int N)
{
int k,l,n;
double distK = 0, fark = 0;
for(n=0; n < N; n++) {
minDistKpp[n] = 1e10;
minDistIdx[n] = 0;
// her bir kisi icin tum siniflari test et
for(k=0; k < K; k++)
{
distK = 0;
for(l=0; l < L; l++)
{
// her bir oznitelik icin
fark = data[l+n*L]-centroids[l+k*L];
distK += fark*fark;
}
if(distK < minDistKpp[n]) {minDistKpp[n] = distK; minDistIdx[n] = k;}
}
}
}
Bir diğer önemli fonksiyon updateCenters ise findMinDist tarafından atanan etiket değerlerini kullanarak yeni sınıf ortalamalarını hesaplamaktadır. Hesaplanan merkez değerler yeni merkezleri gösteren Ncentroids değişkenine yazılmaktadır.
void updateCenters(double *data, double *centroids, double *minDistKpp, int *minDistIdx, int K, int L, int N)
{
int k,l,n;
double distK = 0, fark = 0;
int *totalIdx = (int*) calloc(K, sizeof(int));
memset(centroids,0,K*L*sizeof(double));
for(n=0; n < N; n++)
{
k = minDistIdx[n];
totalIdx[k]++;
for(l=0; l < L; l++)
{
// herbir öznitelik için
centroids[l+k*L] += data[l+n*L];
}
}
// Sinif ortalamalarini guncelle
for(k=0; k < K; k++)
{
double frac = 1.0/totalIdx[k];
for(l=0; l < L; l++)
{
centroids[l+k*L] *= frac;
}
}
free(totalIdx);
}
Yukarıda verilen kod parçasında ilk for döngüsünde aynı sınıfa ait olan noktalar toplanmış ve her sınıfta kaç nokta olduğu totalIdx
değişkeninde saklanmıştır. İkinci for döngüsü ise grup içi toplamları eleman sayısına bölerek küme ortalamalarını bulmak için kullanılmıştır.
Algoritma adımında birinci sırada yer alan intialCentroids kısmını neden son kısma bıraktığımı düşünebilirsiniz. Kodlama açısından
en kolay fonksiyon bu olsa da, k-ortalama algoritmasının en zayıf noktası bu adımdır. Yukarıda resimle yaptığım örnekte aklınıza ilk
rastgele merkez atamasının kötü yapıldığı durumda ne olacağının gelmiş olmasını umuyorum. Bu durumu bir örnek ile incelemeye çalışalım.
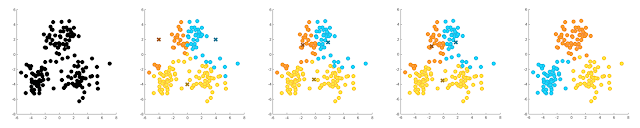
Yukarıdaki örnekte küme merkezleri rastgele seçilirken ikinci resimdeki gibi seçilmiştir. Bu küme merkezlerine göre yapılan ilk etiket ataması ise yine ikinci resimde gösterilmiştir. İkinci iterasyonda algoritma küme merkezlerini ilk aşamada atanan etiketleri kullanarak (mavi kümenin merkezi mavi noktaların ortalaması, turuncu grubun merkezi turuncu gruba ait noktaların ortalaması ve sarı kümenin merkezi sarı noktaların ortalaması) bulduğundan üçüncü resimde x ile gösterilen sonuca ulaşılmıştır. Bu merkezler kullanılarak grup ataması yaıldığında ise yine üçüncü resimde gösterilen kümeleme elde edilmiştir. Üç iterasyon sonucu elde edilen sonuç (dördüncü resim) gerçek sonuç (beşinci resim) ile karşılaştırıldığında çoğu örneğin yanlış kümelenmediği görülebilir.
Bu nedenle ilk merkezlerin atanması için bazı rastgele seçimden daha akıllı yöntemler kullanmamız gerektiğini düşünebilirsiniz.
Bu düşünce bizi k-means++ algoritmasına getirmektedir [2]. 2007 yılında önerilen bu algoritma ilk merkez seçimlerinin rastgele yapılması yerine başlangıç hatasını azaltacak şekilde yapılmasını önermektedir. Bu yönteme göre K ilk ortalama şu şekilde seçilir;
1. İlk merkezi rastgele seç
2. Herbir noktanın merkezlere olan en küçük uzaklığını hesapla
3. Bu uzaklığı seçilme olasılığı olarak kullanarak yeni bir merkez seç
4. Toplam K merkez seçilene kadar 2-3 tekrarla
Görüleceği üzere mantık oldukça basit. Her seçilen merkezin bilgisi noktalar üzerinde kullanılarak merkezlere en uzak noktalar seçilmeye çalışılmakta. Ayrıca ikinci adımda verilen işlem için gerekli kodu findMinDist fonksiyonu içerinde yazdığımızdan, yapmamız gereken işlem sayısı oldukça kısalmakta.
void intialCentroids(double *data, double *Ocentroids, int K, int L, int N)
{
// kmeans++ algorithm to find the initial centroids
int FirstN = rand() % N;
memcpy(Ocentroids,(data+FirstN*L),L*sizeof(double));
findMinDist(data,Ocentroids,minDistKpp,minDistIdx, 1, L, N);
for(k=1; k < K; k++) {
sumDistKpp = 0;
for(n=0; n < N; n++) { sumDistKpp += minDistKpp[n]; }
sumDistKpp = sumDistKpp*rand() / (RAND_MAX-1);
for(n=0; n < N; n++) {
if ((sumDistKpp -= minDistKpp[n]) > 0) continue;
break;
}
newN = n;
memcpy(Ocentroids+k*L,(data+newN*L),L*sizeof(double));
findMinDist(data,Ocentroids,minDistKpp,minDistIdx, k+1, L, N);
}
}
Verilen kodda rastgele fonksiyonu ile ilk merkez noktası rastgele olarak seçiliyor ve ardından findMinDist fonksiyonu
ile seçilen bir merkez olduğundan K=1 alınarak tüm noktaların merkeze olan uzaklıkları minDistKpp hesaplanıyor. Ardından bu uzaklıklar o noktanın seçilme olasılığını gösterecek şekilde yeni bir rastgele nokta ikinci merkez olarak seçiliyor. Artık elimizde iki nokta olduğundan findMinDist fonksiyonu ile yapılan uzaklık hesaplaması K=2 alınarak yapılıyor ve tüm merkezler seçilene kadar işlem devam ediyor. Aşağıda bu seçim yönteminin sonuca olan etkisi farklı bir örnek kullanılarak verilmiştir.
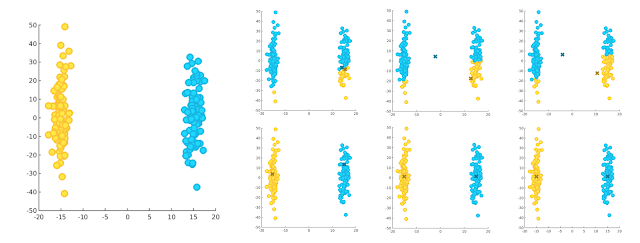
Verilen ilk imge iki kümeye ait orjinal dağılmları göstermektedir. Yukarı sırada verilen imge dizisi küme merkezlerinin rastgele atanması ile başlanan iterasyonun ilk üç adımını, aşağı sırada verilen imge dizisi ise k-means++ algoritması ile başlanan iterasyonun ilk üç adımını göstermektedir. Görüldüğü üzere ilk merkez atamalarının birbirlerine yakın olmasından dolayı ilk yöntem doğru bir sınıflama yapamamıştır. k-means++ algoritması çok yüksek olasılıkla k-means algoritmasından daha iyi sonuçlar üretecektir. Ancak k-means++ algoritmasının da ilk merkezleri kötü seçme olasılığı bulunmaktadır. Bunu engellemek içinse genellikle k ortalama algoritması 100 kez çalıştırılır ve her seferinde üretilen son kümelemenin hatası hesaplanır ve bu hatalar içerisinden en küçük olan kümeleme sonucu nihai sonuç olarak kabul edilir.
Referanslar
-
X. Wu, V. Kumar, J. R. Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J. McLachlan, A. F. M. Ng, B. Liu, P. S. Yu, Z.-H. Zhou, M. Steinbach, D. J. Hand, and D. Steinberg, “Top 10 algorithms in data mining” Knowledge and Information Systems 14.1 (2008): 1-37.
-
Arthur, D., & Vassilvitskii, S. (2007, January). “k-means++: The advantages of careful seeding.” In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms (pp. 1027-1035). Society for Industrial and Applied Mathematics.